 2024-08-27
2024-08-27 阅读:1399
阅读:1399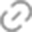 来源:曲速超为
来源:曲速超为接上篇
IBM Telum II 处理器和 Spyre AI芯片
在 Hot Chips 2024 上,IBM 推出了 Telum II 处理器和 Spyre AI 芯片。其中,IBM Telum II 是 IBM 的下一代大型机处理器。

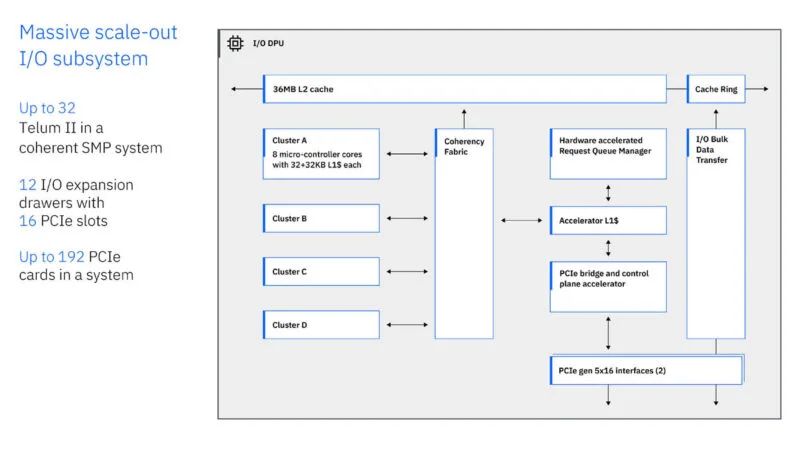
以下是该芯片的一些关键部件。有 10 个 36MB 的 L2 缓存,其中有八个 5.5GHz 内核以固定频率运行。还有一个板载 AI 加速器,速度为 24 TOPS。IBM 集成了一个“DPU”。

DPU 必须处理数以万计的未完成 I/O 请求。它不是将 DPU 放在 PCIe 总线后面,而是以连贯方式连接并拥有自己的 L2 缓存。IBM 表示,这可以提高性能和能效。
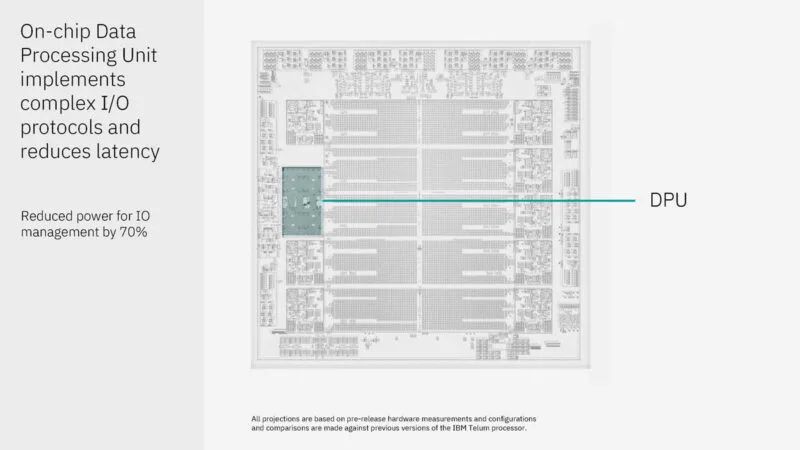
这是 DPU 图。有四个集群,每个集群有八个微控制器。IBM 运行自己的自定义协议。板载 DPU 允许它使用这些微控制器来实现这一点。
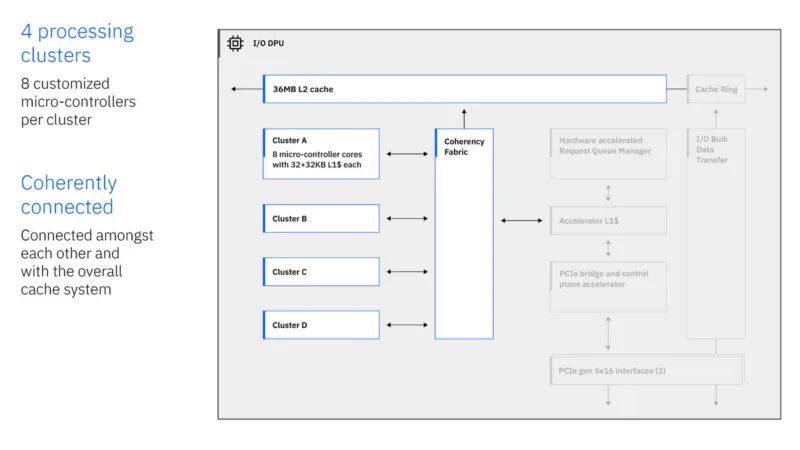
DPU 还具有 PCIe Gen5 x16 接口。IBM 正在此 DPU 中运行自己的定制 ISA 等。
完整的系统最多可有 192 个 PCIe 卡,每个卡有 12 个 I/O 扩展抽屉和 16 个 PCIe 插槽。
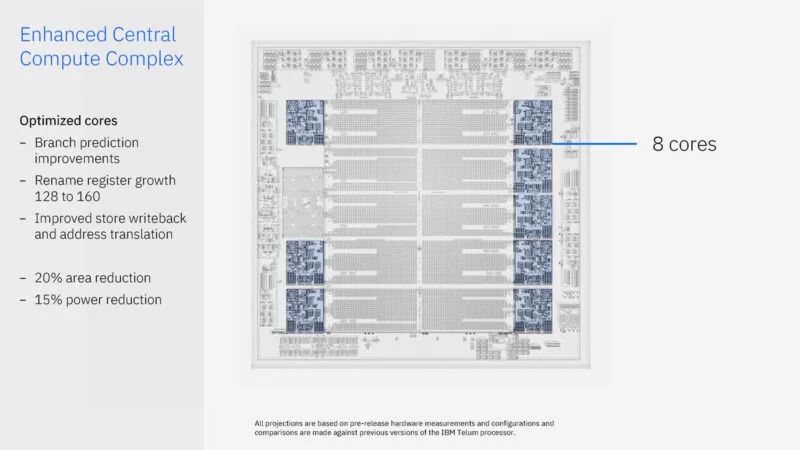
IBM 也对其核心进行了修订。有趣的是,布局规划中只有很少一部分是专门用于核心的。
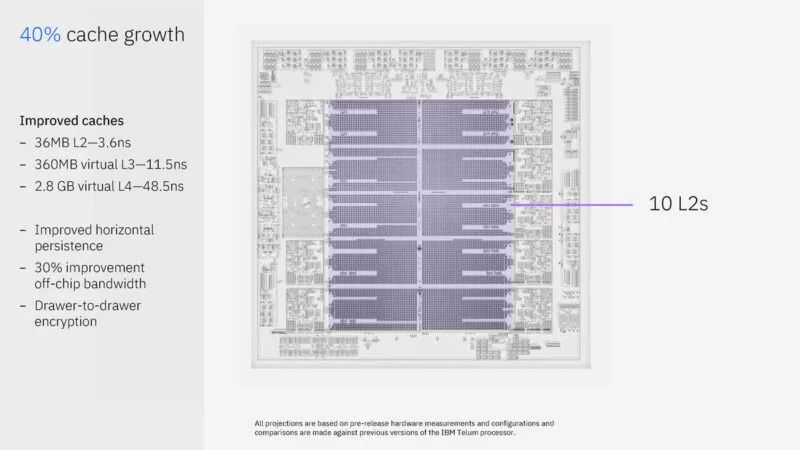
十个 36MB 的 L2 缓存速度很快,但还有更多。有一个 360MB 的虚拟 L3 缓存和 2.8GB 的虚拟 L4 缓存。IBM 的芯片宣传了 L2 缓存中的可用空间量,并且可以在其他地方使用该缓存。
IBM 使用的是三星 5nm。核心运行频率固定为 5.5GHz。
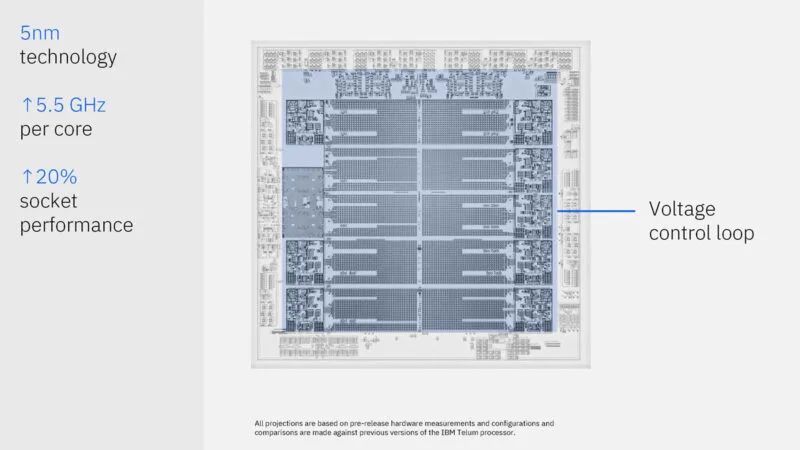
Telum II 具有一个新的电压控制环路,可以帮助核心以 5.5GHz 的速度运行,同时处理器上的工作负载会有所不同。
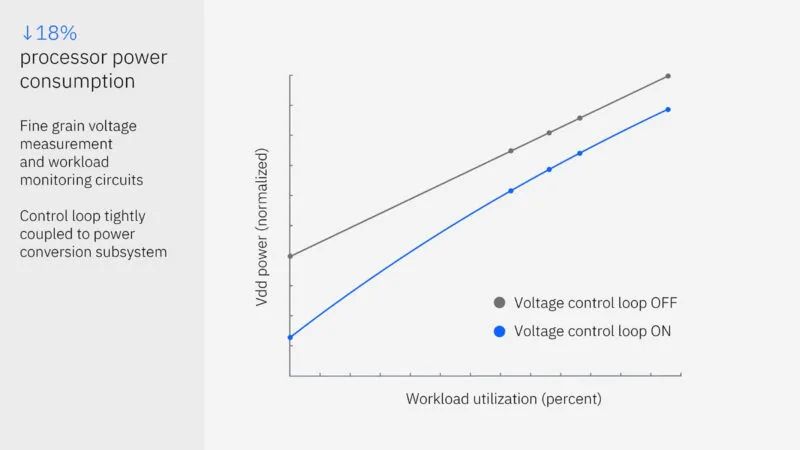
接下来是IBM的AI表现。

IBM 正在专门为其企业客户设计 AI 加速器。
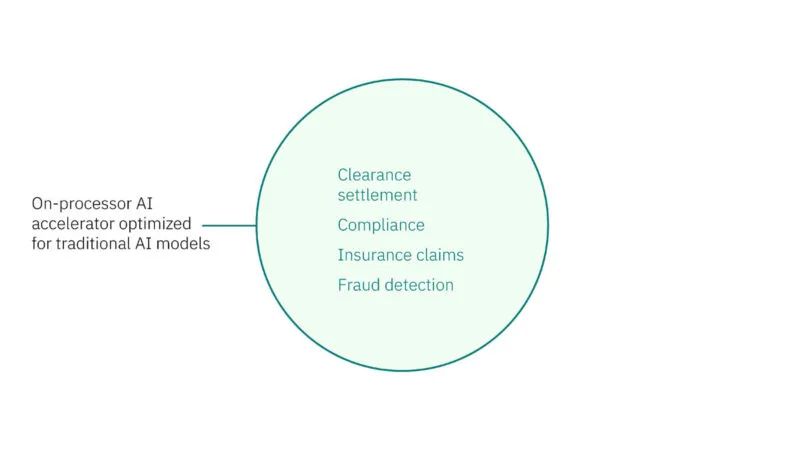
IBM Spyre 用于优化使用具有不同精度的大型和小型模型。
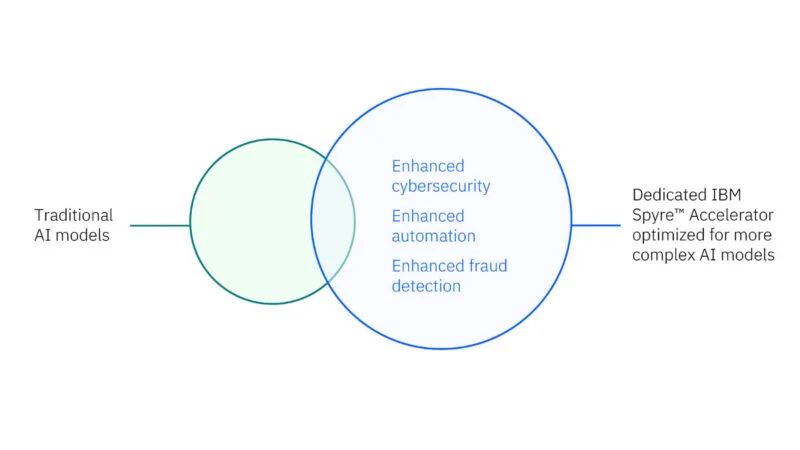
如除了针对某些交易的较大模型之外,用于欺诈检测的传统小型高效模型也变得越来越普遍。
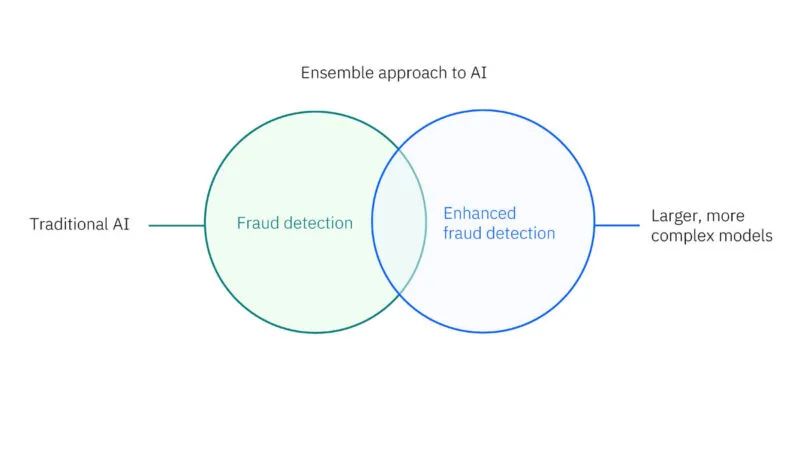
当加速器进行计算时,Telum II 将处理器上的 AI 加速作为 CISC 指令实现。
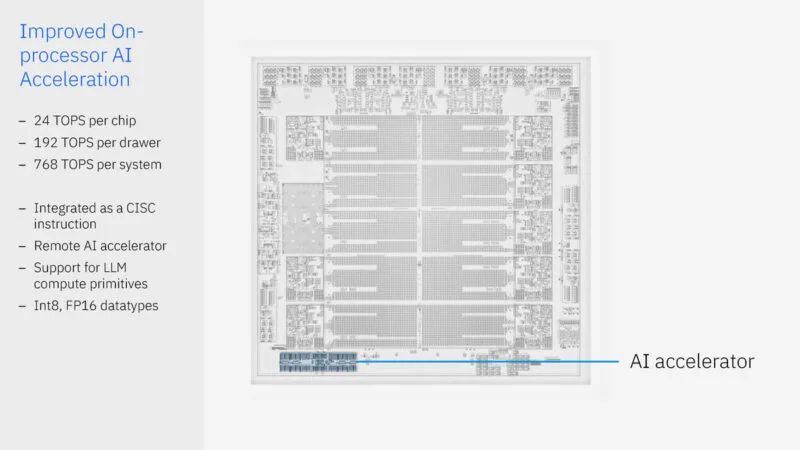
这是 IBM Spyre Accelerator PCIe 卡。这些卡具有 128GB 的LPDDR5 内存,运行速度为 300TOPS,功耗仅为 75W。这适用于 LLM 之类的模型太大而无法装入处理器芯片的情况。

这是芯片,32 个内核中的每一个都有 2MB 的暂存器,用于保存数据,但不是缓存。因此,IBM 不需要标准的缓存管理系统。

以下是处理图块的情况。
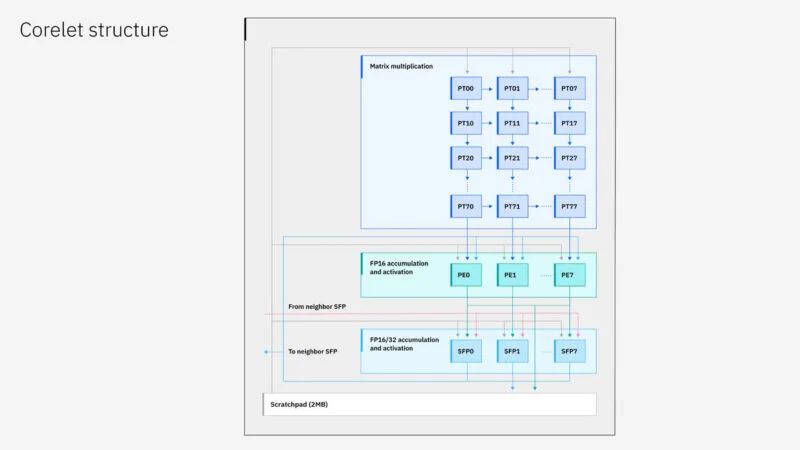
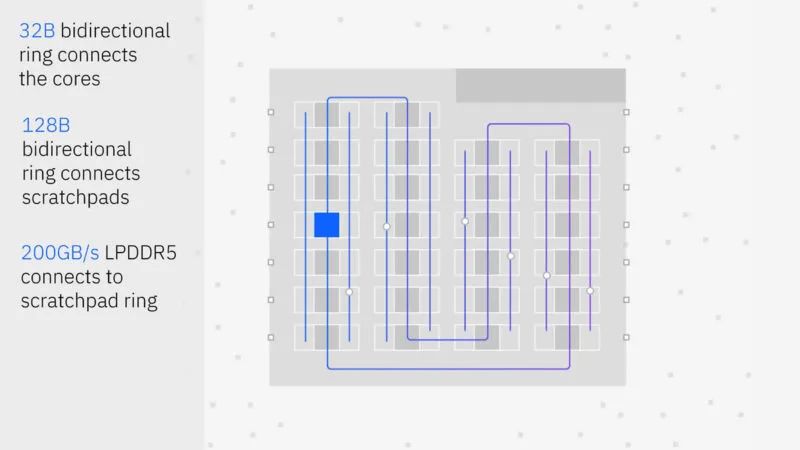
芯片上有多种结构。
IBM 一直在研究预测性人工智能,但它也在研究 Spyre 上的生成性人工智能。
每个抽屉有 8 张卡,总计 1TB 的内存。

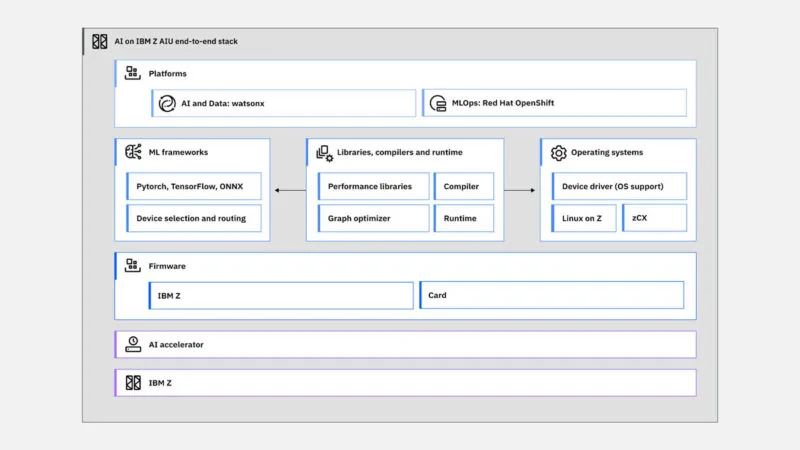
这是 IBM Z 软件堆栈上的 AI。
Telum II 和 Spyre 均基于三星 5nm 工艺制造,但采用不同的工艺版本。以下是部分规格:

IBM 表示,一个装有 96 张 Spyre 卡的测试 IBM Z 系统可以达到高达 30 PetaOps 的性能。这些是为完全不同的用例设计的完全不同的芯片。可靠性是关键,在处理 I/O 和保持可靠性的同时提供性能提升的工程设计非常酷。
SK Hynix 人工智能专用计算内存解决方案
在 Hot Chips 2024 上,SK Hynix 的重点不只是 AI 加速器的标准 DRAM。相反,该公司展示了其在内存计算方面的最新进展,这次是使用 AiMX-xPU 和 LPDDR-AiM 进行 LLM 推理。其想法是,无需将数据从内存移动到计算以执行与内存相关的转换,而是可以直接在内存中完成这些转换,而无需遍历互连。这使得它更节能,速度也更快。
SK Hynix 声称其热爱法学LLM,因为它们与存储有关。
该公司正在展示其采用 Xilinx Virtex FPGA 和特殊 GDDR6 AiM 封装的 GDDR6 内存加速器卡。

以下是该卡片的外观。

这是 GDDR6 芯片。我们在 FMS 2024 上再次看到了它们,但我们已经有了它们的照片。

此外,SK Hynix 提到了我们拍摄这些照片的 OCP 2023 现场演示。

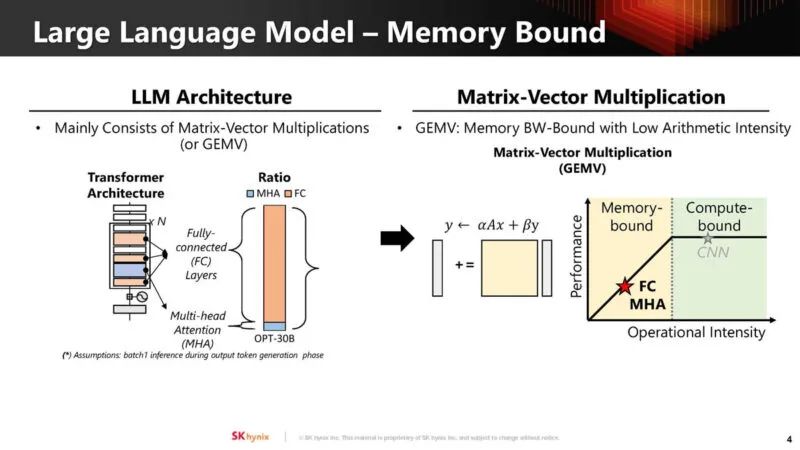
这是 LLM 的完全连接层和多头注意力(multi-head attention)存储和计算边界部分。
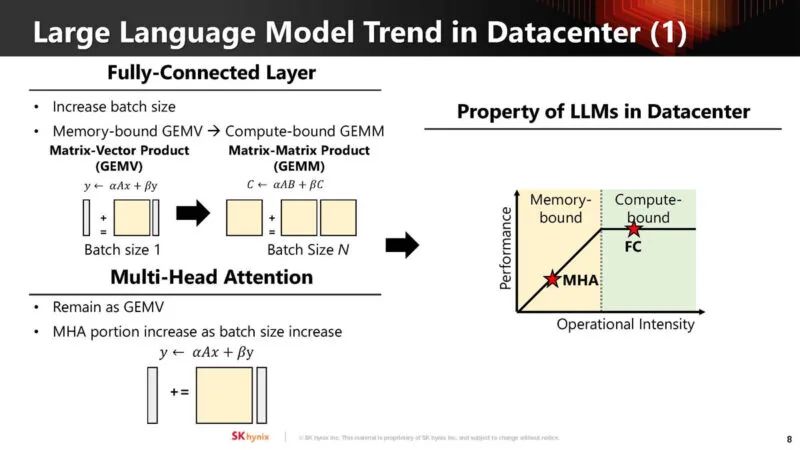
以下是压力如何根据批次大小(batch size)而变化。
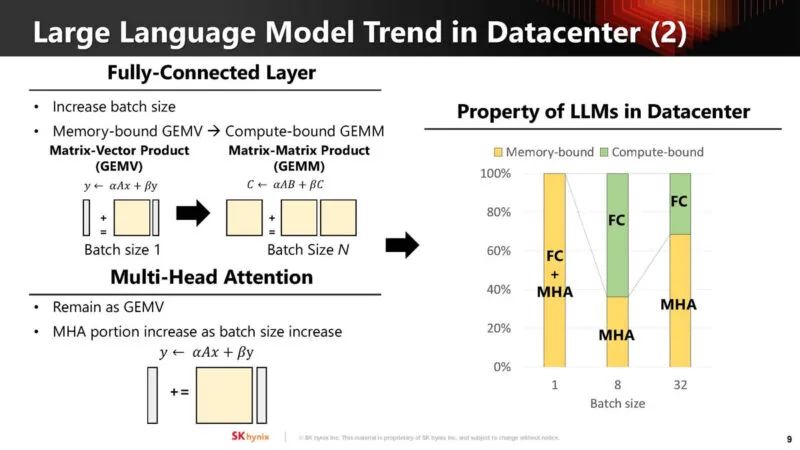
SK Hynix 将多头注意力映射到 AiM。
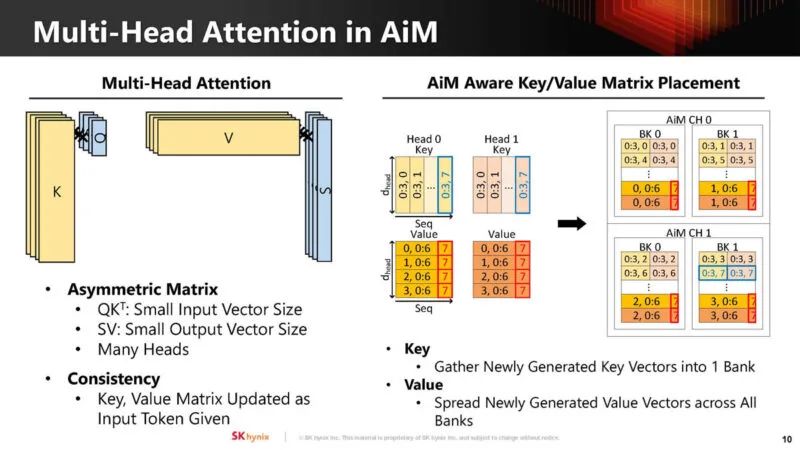
该公司还利用 32 个 AIM 封装将内存容量从 16 个增加到 32GB,增加了一倍。32GB 对于产品来说可能不够,但对于原型来说却足够了。尽管如此,该公司还是能够展示该技术的性能。

下一代演示将会展示类似 Llama-3 的东西,该公司还在考虑将每张卡的容量从 32GB 扩展到 256GB。

除了数据中心 AI,该公司还在关注设备上的 AI。我们已经看到苹果、英特尔、AMD 和高通等公司正在推动 AI 的 NPU。
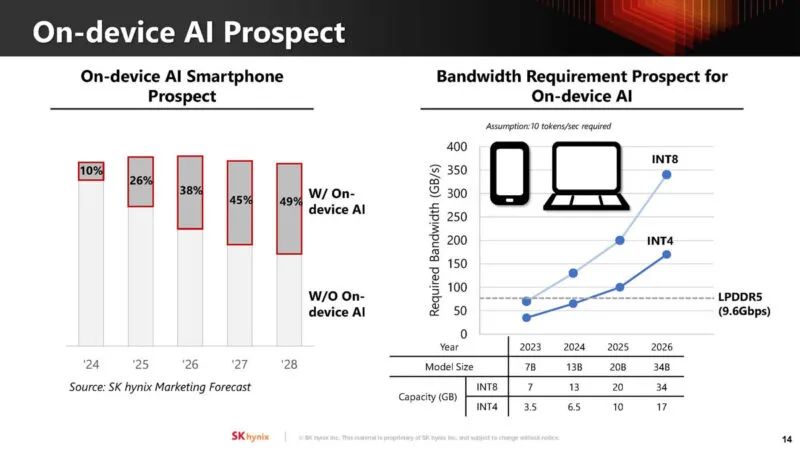
设备上的 AI 通常会降低批处理大小,从而使这些工作负载受到内存限制。将计算移出 SoC 意味着它可以更节能,并且不会占用 SoC 上的计算芯片空间。
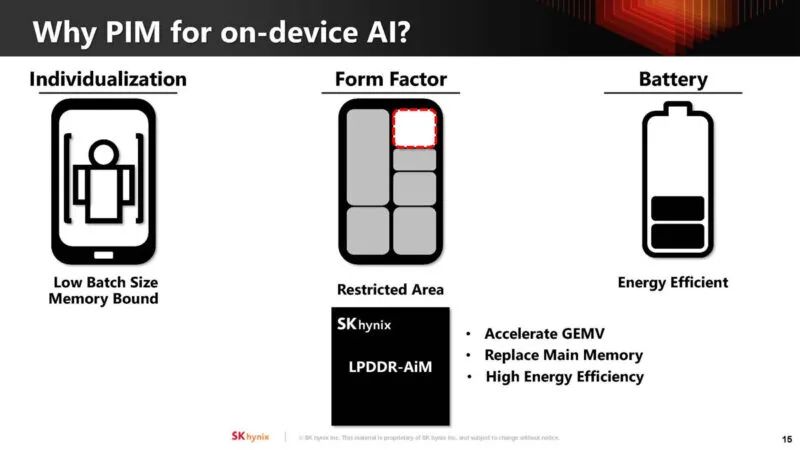
目标是在未来针对 LPDDR5-AiM 产品优化 AiM。目标是不改变现有的 LPDDR 命令,并且不会对性能产生负面影响。本表上的规格为估计值。
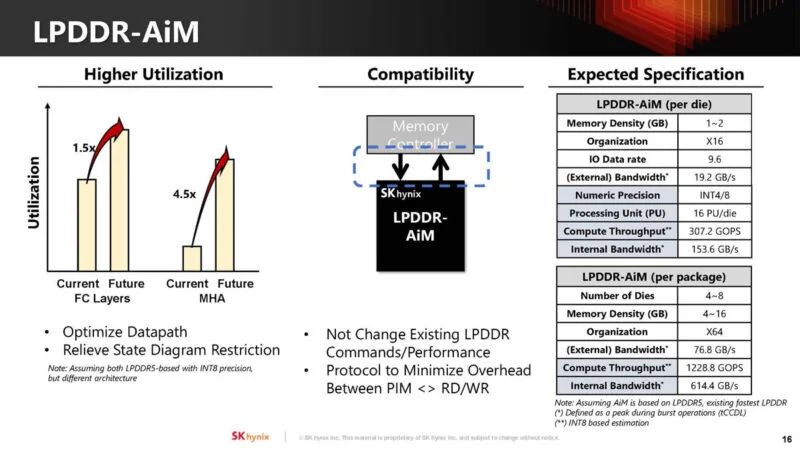
借助LPDDR5,可以将其集成到移动设备的SoC上。
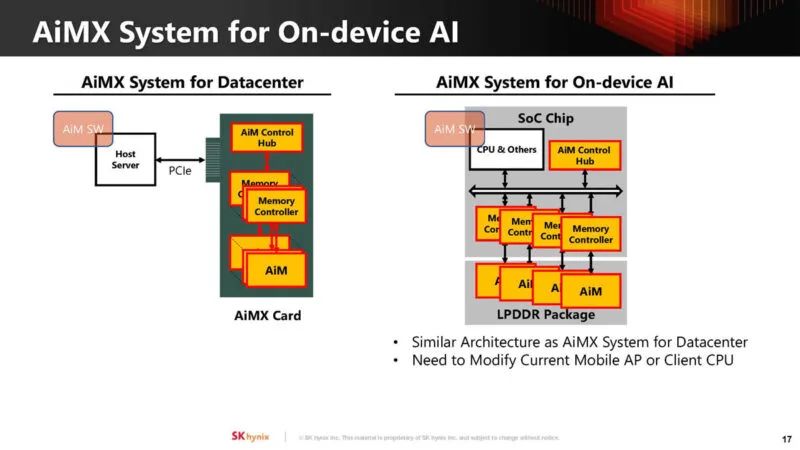
对于不同的应用可能需要做出不同的权衡。
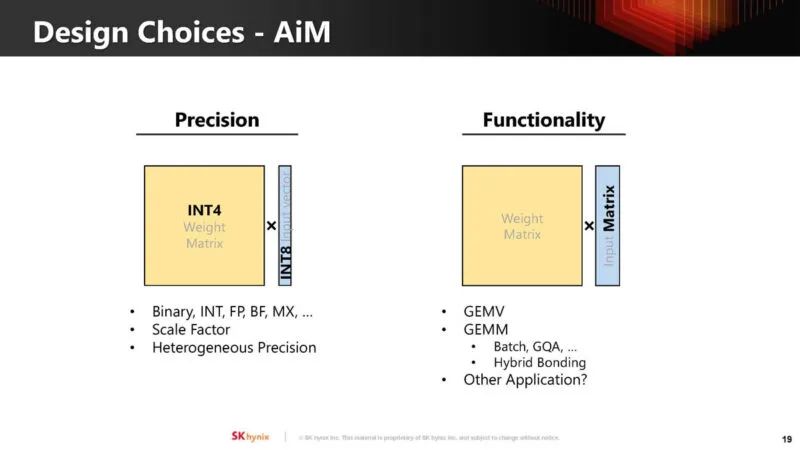
其中一个挑战是协调 LPDDR 内存的正常使用情况和计算需求。此外,还可能改变芯片的散热和功率要求。

另一个挑战是如何对 AiM 进行编程。
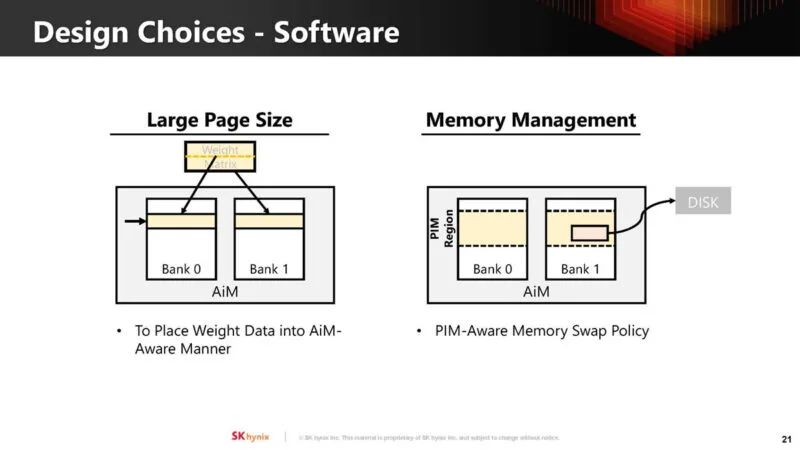
看起来 SK Hynix 正在扩大 AiM/AiMX 的使用范围和类型。
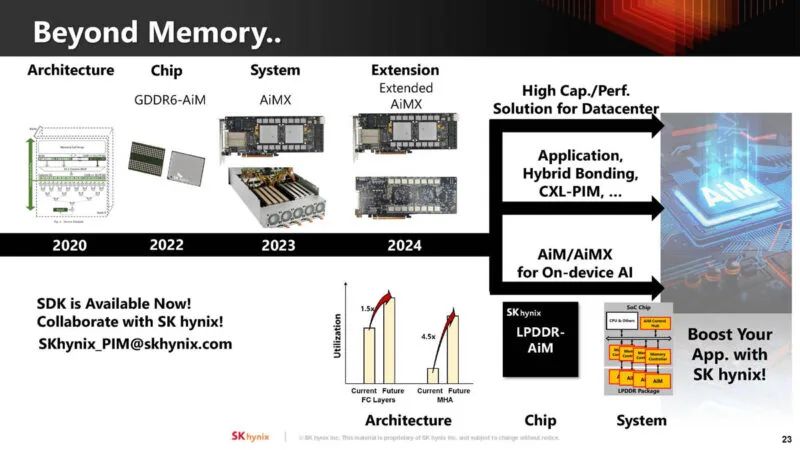
SK Hynix 表示,GDDR6 中 AiM 占据了芯片面积的 20% 左右。
虽然感觉很不错,但这仍然感觉像是主流 SoC/芯片供应商必须采纳并整合才能成为主流的东西。从很多方面来看,内存计算可能有意义。我们将在未来看到它是否会从原型变成产品。
适用于万亿参数 AI 模型的 SambaNova SN40L RDU
在 Hot Chips 2024 上,主题显然是人工智能。SambaNova SN40L RDU 是该公司针对万亿参数规模人工智能模型时代的首款设计。
新的 SambaNova SN40L “Cerulean” 架构。这是一款 5nm TSMC 芯片,具有三层内存,非常不错。它还是一种数据流架构,旨在用作训练和推理芯片

三层内存分别是 520MB 的片上 SRAM。然后是 64GB 的 HBM。然后是额外的 DDR 内存作为容量层。SambaNova 在这里展示了一个 16 插槽系统,以获得 8GB 的片上 SRAM 和 1TB 的 HBM 等功能。

以下是 SambaNova 图块中的 1040 个计算和内存单元及其网格交换机。
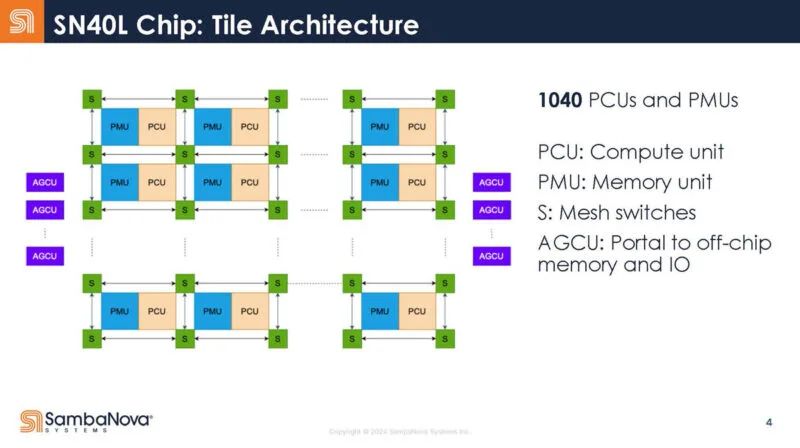
这是计算单元。它没有传统的提取/解码等执行单元,而是具有一系列静态阶段。PCU 可以作为流式传输单元运行(数据从左到右),蓝色是跨通道缩减树。在矩阵计算操作中,它可以用作脉动阵列。
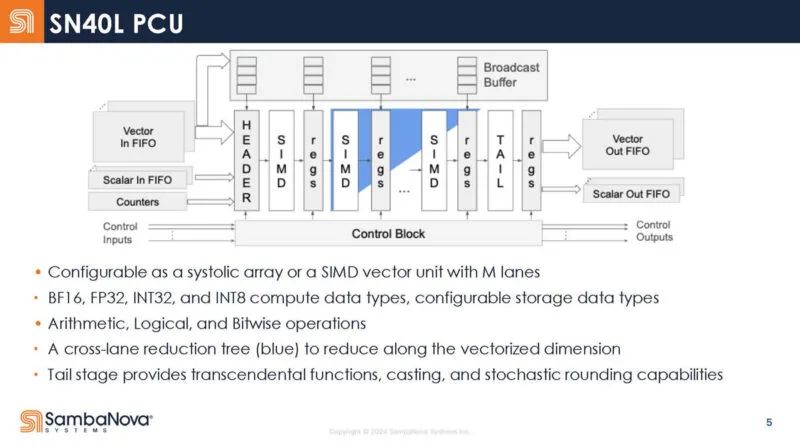
这是高级内存单元框图。这些是可编程管理暂存器,而不是传统的缓存。
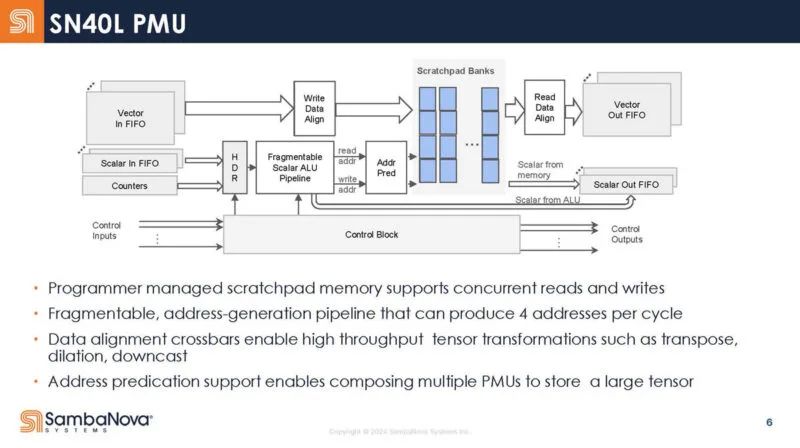
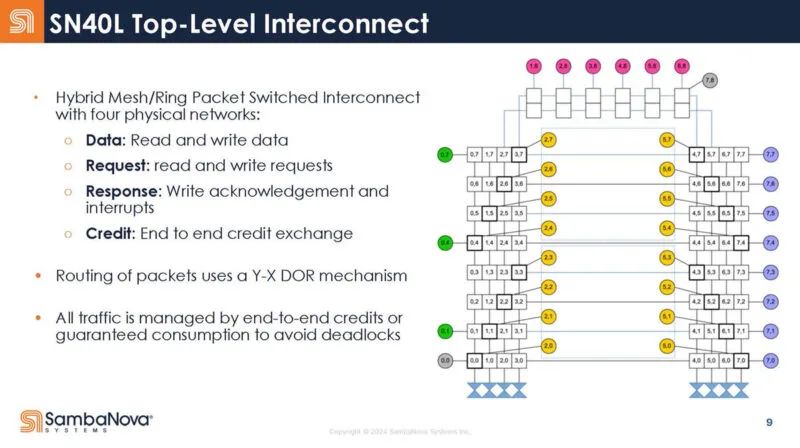
该芯片还具有网状网络。物理网络有三种:矢量、标量和控制。

AGCU 用于访问片外存储器(HBM 和 DDR),而 PCU 用于访问片上 SRAM 暂存器。

这是顶层互连。
下面是 Softmax 如何被编译器捕获然后映射到硬件的示例。
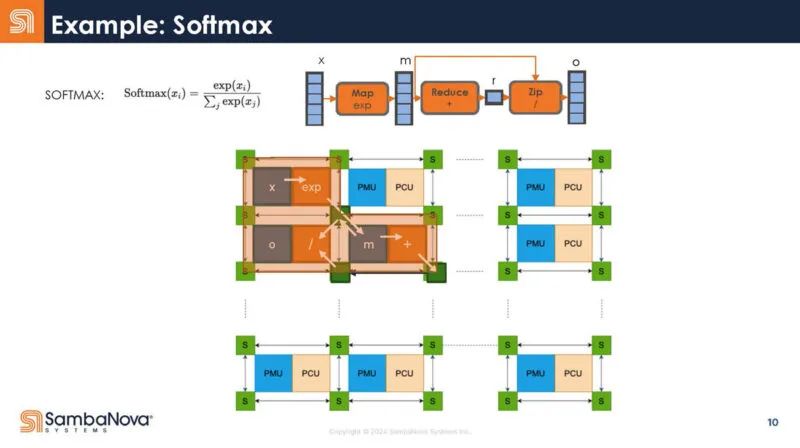
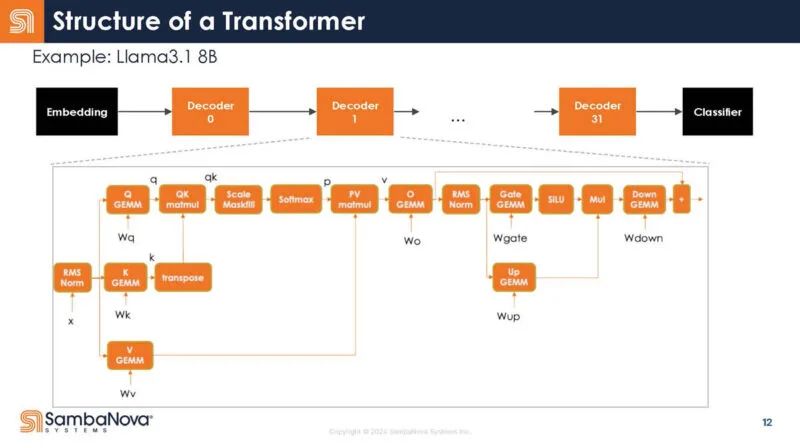
将其映射到 LLM 和 GenAI 的转换器模型,以下是映射。查看解码器内部,有许多不同的操作。
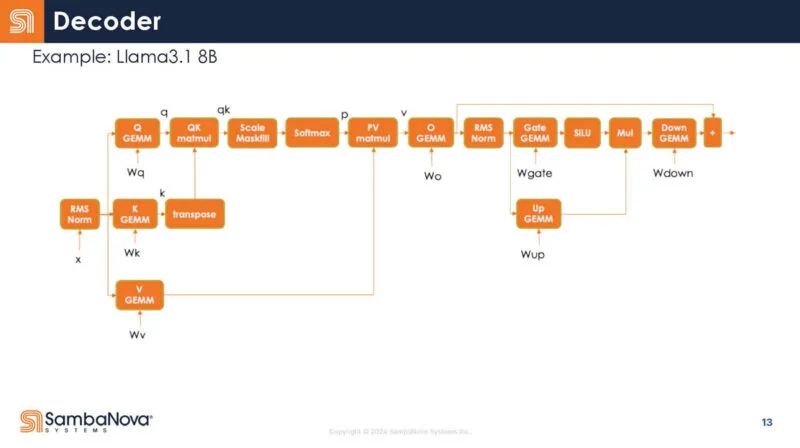
以下是解码器的放大图。每个框都是一个运算符。同时,通常您会运行多个运算符,并将数据保存在芯片上以供重复使用。
以下是 SambaNova 对如何在 GPU 上融合运算符的猜测。他们指出这可能并不准确。
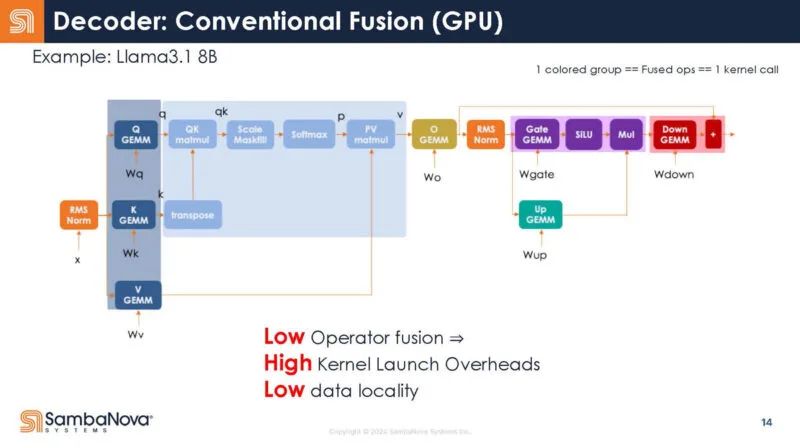
在 RDU 中,整个解码器就是一个内核调用。编译器负责这个映射。
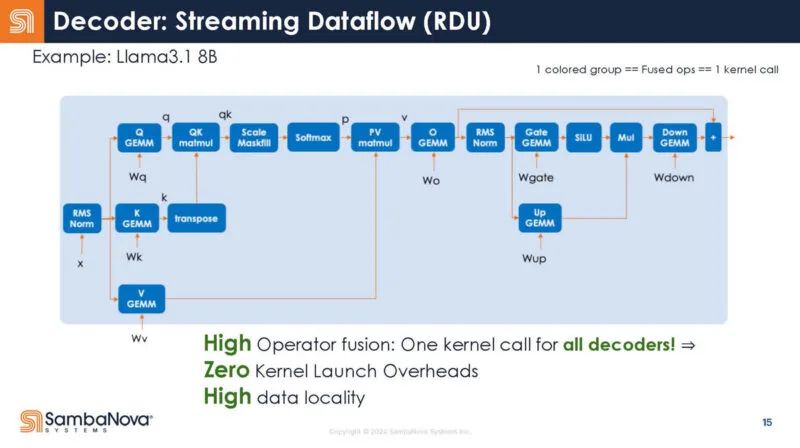
这张幻灯片只是解码器映射的一张“酷图”。

回到 Transformer 的结构,这里是解码器的不同函数。你可以看到,每个函数调用都有启动开销。
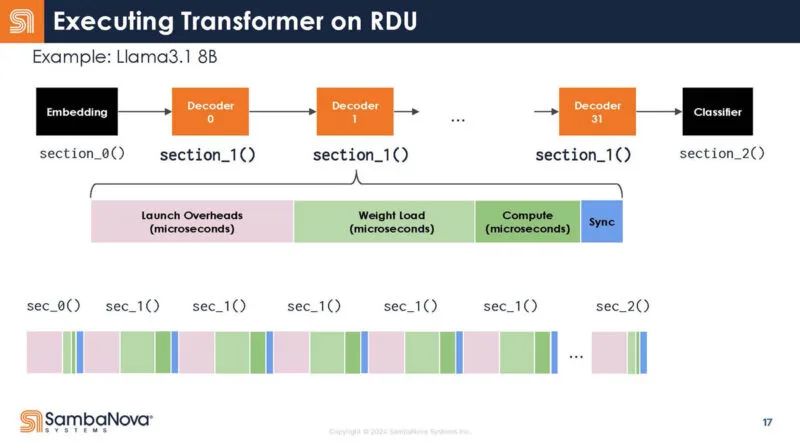
它不是 32 次调用,而是写为一次调用。
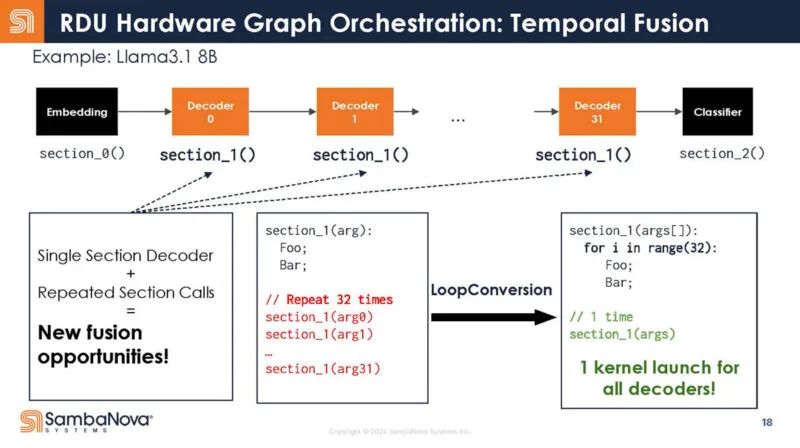
换言之,这意味着调用开销更少,因为只需一次调用,而不是多次调用。因此,你增加了芯片对数据进行有用工作的时间。
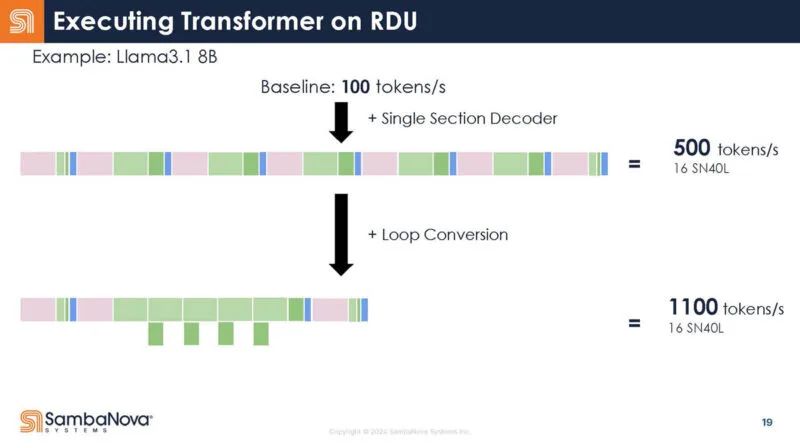
这是 SambaNova 在 llama3.1 上的表现。这里有一个二维码。这是 SambaNova 的。我们建议不要使用它,因为……好吧,谁知道呢。
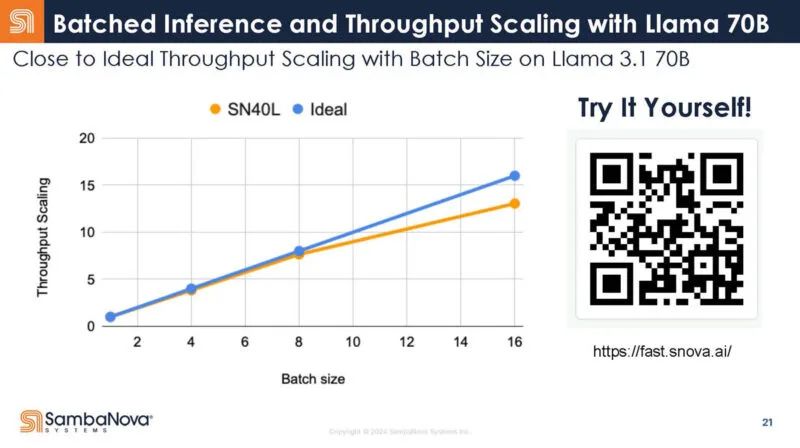
因此,SambaNova 表示它拥有一款引人注目的推理产品。DDR 用于混合专家模型检查点。板载 DDR 意味着 SambaNova 无需前往主机 CPU 来获取该数据。或者,您需要更多 GPU 来保存专家模型的所有这些检查点。该 DDR 在模型切换方面有很大帮助。
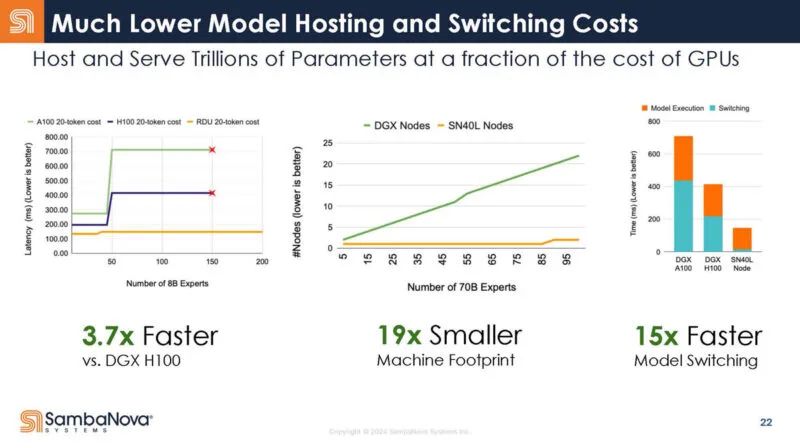
这是有关训练的幻灯片。
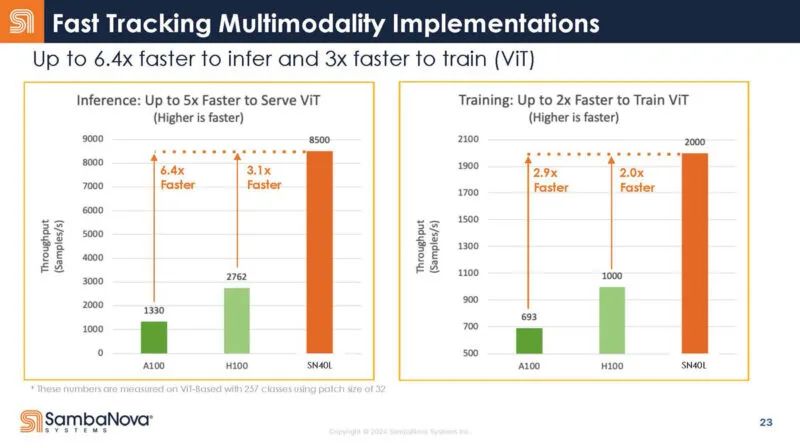
总的来说,这是很酷的东西。看到这家公司的加速器真是太酷了。
OpenAI:构建可扩展AI基础设施
在 Hot Chips 2024 大会上,OpenAI 发表了长达一小时的主题演讲,主题是构建可扩展的 AI 基础设施。这很有意义,因为 OpenAI 作为一个组织使用了大量计算,并且未来几年可能会使用更多计算。

我认为我们的大多数读者都熟悉 ChatGPT 和 OpenAI 以及 LLM 的工作原理。我们将只展示接下来的几张幻灯片。


从规模上看,2018 年的想法是——GPT-1 很酷。GPT-2 更加连贯。GPT-3 具有情境学习功能。GPT-4 实际上很有用。人们期望未来的模型在新的行为下会更有用。
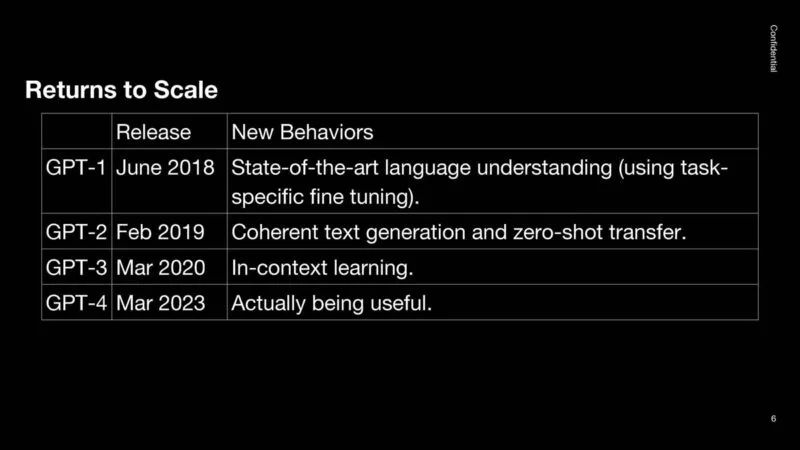
一个重要的观察结果是,扩大规模可以产生更好、更有用的人工智能。

问题是 OpenAI 如何知道训练更大的模型是否会产生更好的模型。OpenAI 观察到,每次计算量翻倍,它都会得到更好的结果。下图显示计算量增加了四个数量级,而扩展仍然有效。
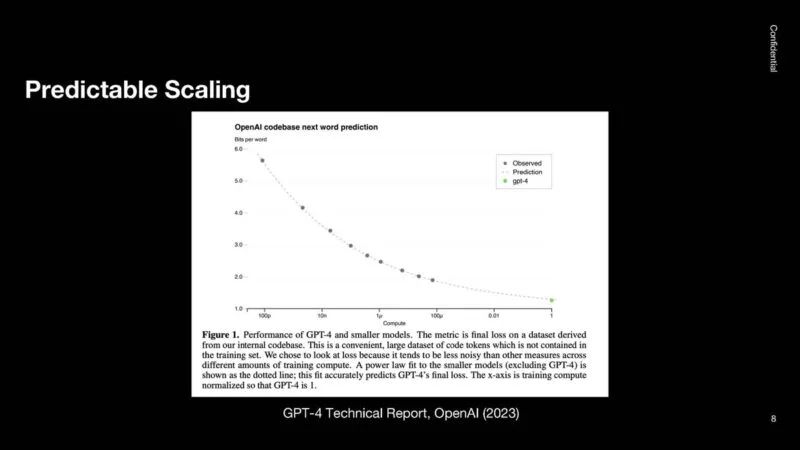
OpenAI 研究了编码等任务,发现存在类似的模式。这是在平均对数尺度上完成的,因此通过/失败不会过分偏向于解决简单的编码问题。
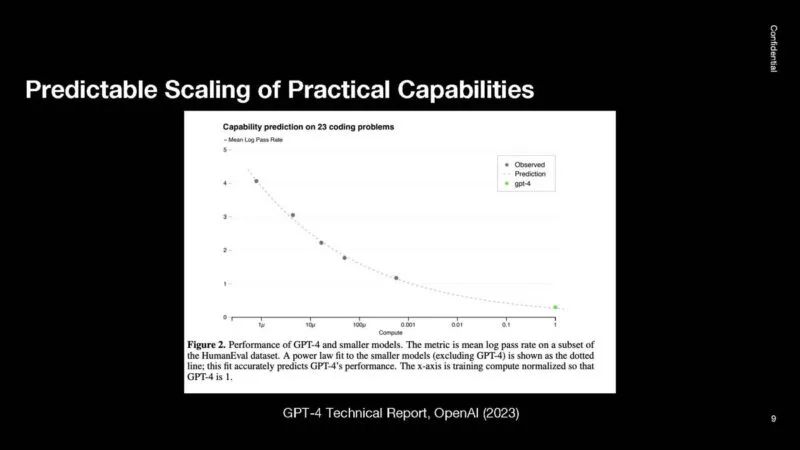
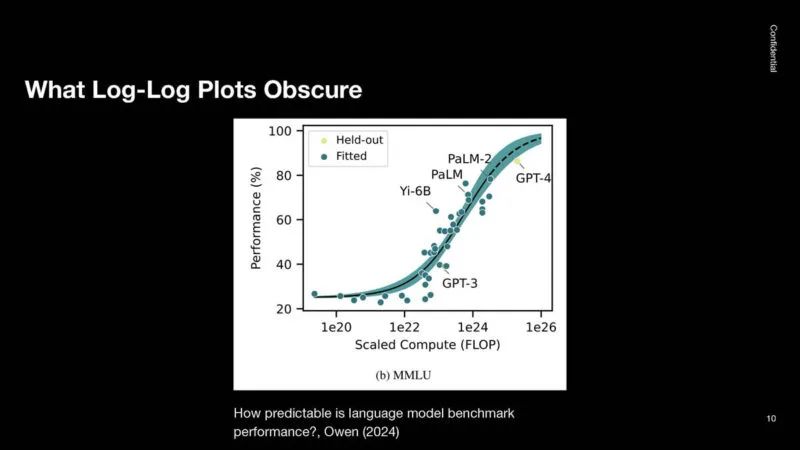
这是 MMLU 基准。这是机器学习基准的终极目标,但由于对数进步,GPT-4 在测试中的得分已经达到约 90%。
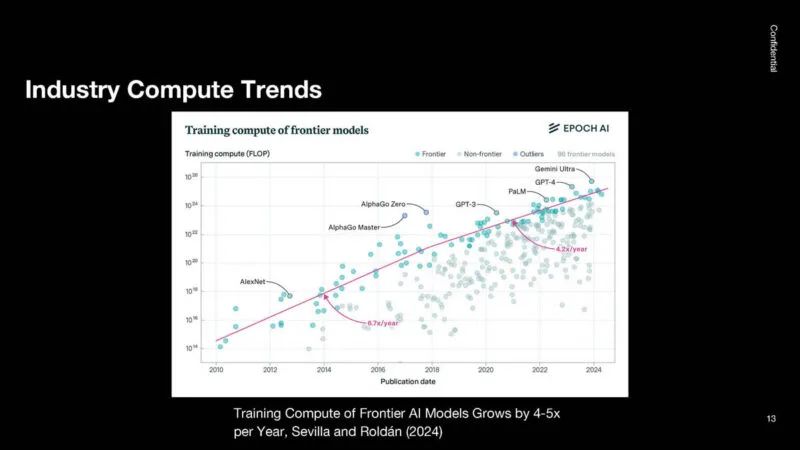
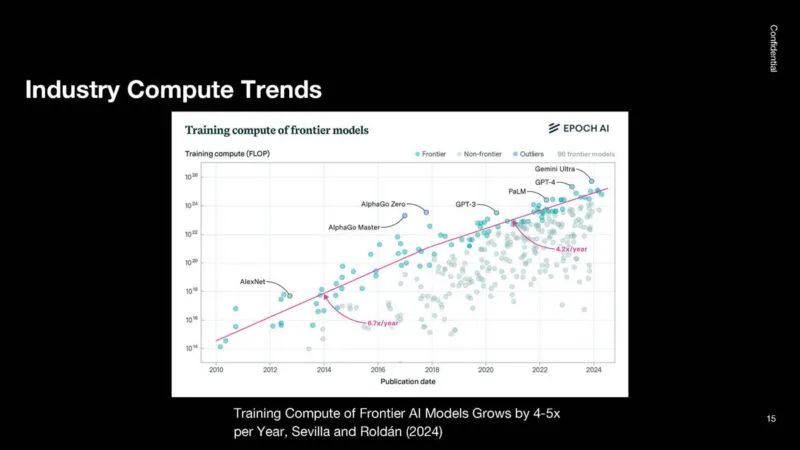
这是用于训练不同前沿模型的行业计算图。自 2018 年以来,它每年增长约 4 倍。
GPT-1 只存在了几周,它已经扩展到使用庞大的 GPU 集群。

2018 年,计算速度从每年 6-7 倍增长到每年 4 倍。2018 年,许多唾手可得的成果已经得到解决。未来,成本和功耗等问题将成为更大的挑战。
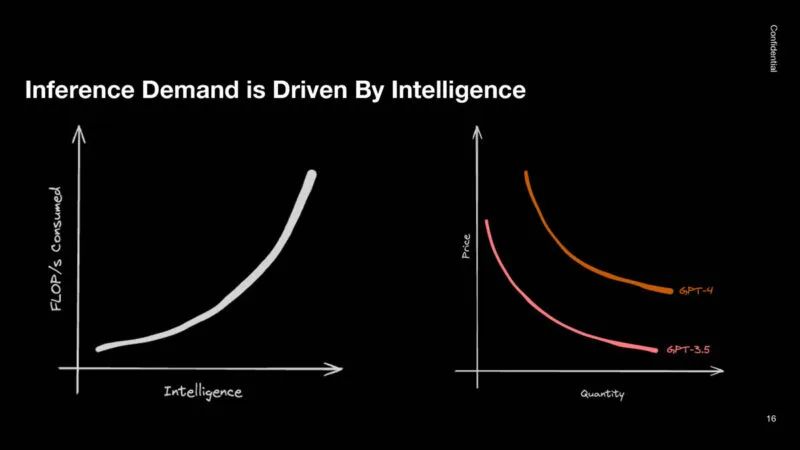
在推理方面,需求由智能驱动。大部分推理计算都用于高端模型。较小的模型往往需要的计算量要小得多。推理 GPU 的需求正在大幅增长。
以下是人工智能计算的三个要点。

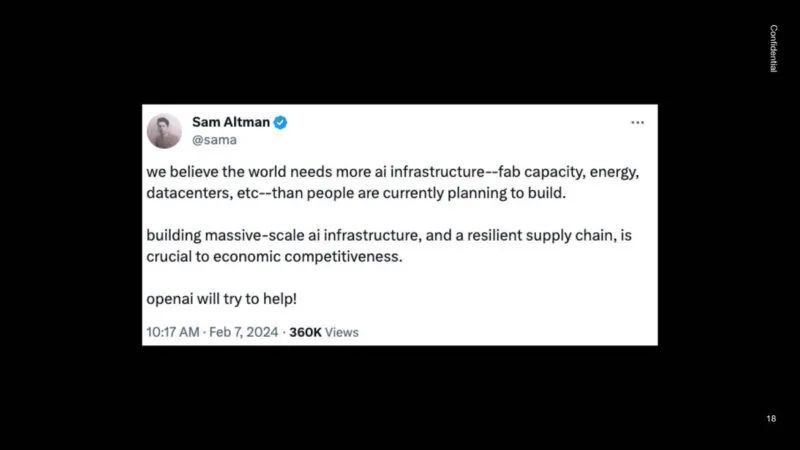
人们认为,世界需要的人工智能基础设施比目前规划的还要多。
这是实际需求(黑色部分),这是专家对需求的预测。尽管这条线一直在上升,但专家们的意见并不统一。
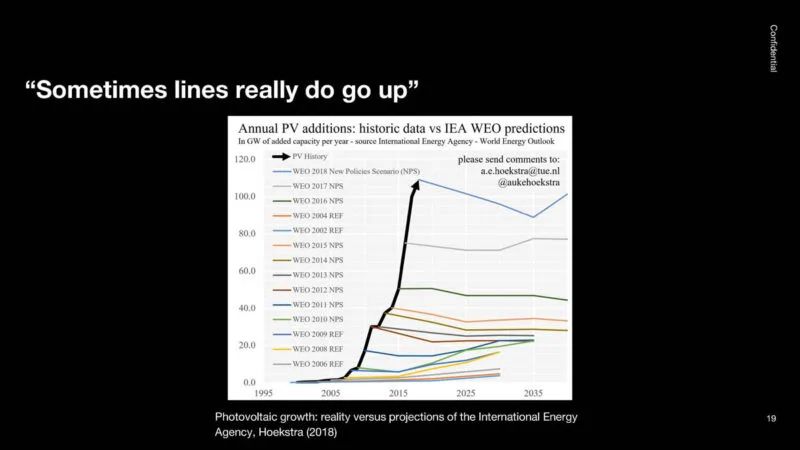
在大约 50 年的时间里,摩尔定律一直直线上升,其时间比很多人认为的要长。
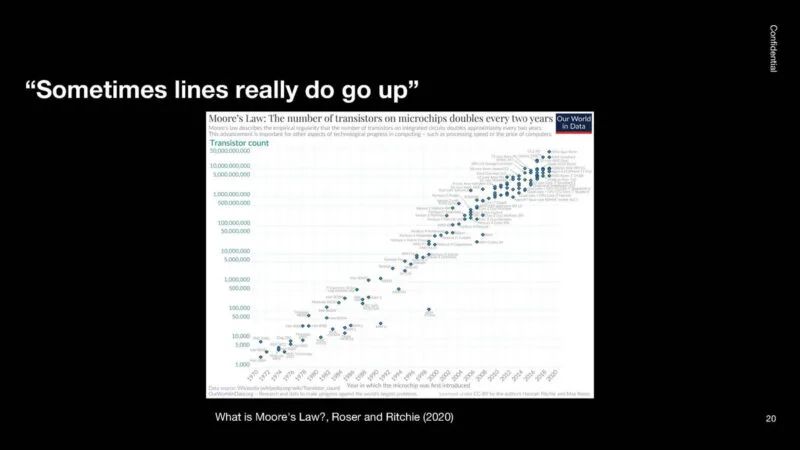
因此,OpenAI 认为 AI 需要大量投资,因为计算能力的提升已经产生了超过 8 个数量级的效益。
OpenAI 表示,我们必须为大规模部署进行设计。RAS 就是一个例子。集群变得如此之大,以至于会发生硬故障和软故障。即使可以隔离 GPU,也会发生静默数据损坏,有时无法重现。集群故障的波及范围很广。

OpenAI 表示,维护成本需要降低。影响半径需要缩小,这样如果一个部件发生故障,其他部件发生故障的几率就会降低。

一个想法是使用优雅降级。这与我们在 STH 托管集群中所做的非常相似,因此不需要技术人员花费时间。验证在规模上也很重要。

电力将是一个重大挑战,因为世界上的电力是有限的。GPU 将同时启动和停止。这给数据中心带来了负载挑战。

就像我们学到的关键经验教训一样,OpenAI 也有一些值得借鉴的地方。我会让你们读一下这些内容:

有趣的是,虽然大家都很注重性能,但性能只是四点之一。
扩展挑战和集群级挑战是巨大的。当我们查看 Top500 时,今天的大型 AI 集群大致与该列表中排名前 3-4 的系统的总和相似。看到大客户谈论他们如何看待对 AI 硬件的需求真是太酷了。
参考链接
https://www.servethehome.com/nvidia-blackwell-platform-at-hot-chips-2024/
https://www.servethehome.com/tenstorrent-blackhole-and-metalium-for-standalone-ai-processing/
https://www.servethehome.com/snapdragon-x-elite-qualcomm-oryon-cpu-design-and-architecture-hot-chips-2024-arm/
https://www.servethehome.com/intel-lunar-lake-for-ai-pcs-at-hot-chips-2024/
https://www.servethehome.com/intel-xeon-6-soc-for-the-edge-hello-granite-rapids-d/
https://www.servethehome.com/ibm-telum-ii-processor-and-spyre-ai-updates-at-hot-chips-2024/
https://www.servethehome.com/sk-hynix-ai-specific-computing-memory-solution-aimx-xpu-at-hot-chips-2024/
https://www.servethehome.com/openai-keynote-on-building-scalable-ai-infrastructure/
https://www.servethehome.com/sambanova-sn40l-rdu-for-trillion-parameter-ai-models/
https://www.servethehome.com/amd-instinct-mi300x-architecture-at-hot-chips-2024/
文章转载自公众号半导体行业观察 编辑部
原文链接:https://mp.weixin.qq.com/s/GHJFcDUSwXw0BVGZk4smDw