 2024-06-12
2024-06-12 阅读:7951
阅读:7951 来源:曲速超为
来源:曲速超为在数字世界的广袤天地里,GPU早已成为每一位玩家、设计师和科研者心中的明珠。谈及GPU,两大巨头NVIDIA和AMD自然是绕不开的话题。说到GPU,怎能不提NVIDIA这位“老大哥”呢?它凭借其深厚的技术积累和源源不断的创新力,一直稳坐市场的头把交椅。无论是游戏画面的逼真呈现,还是设计创作的精细处理,亦或是科研计算的高效加速,NVIDIA GPU都为我们带来了前所未有的体验。
和小编一同回顾下NVIDIA GPU架构的辉煌历程,探寻其背后的技术革新与市场传奇。
真正的GPU,也就是Graphic Processing Unit(图形处理器)的概念,最早是由NVIDIA在1999年发布GeForce 256图形处理芯片时首先提出的。
Tesla
2008年推出,NVIDIA第一个实现统一着色器模型的微架构。经典型号为G80,采用台积电90纳米工艺制程,并实现“五个第一”:第一款支持C语言的GPU;第一款用单一的、统一的处理器取代独立的顶点和像素管道的GPU;第一款使用标量线程处理器的GPU;第一款引入单指令多线程(SIMT)执行模型的GPU;第一次为线程间通信引入了共享内存和屏障同步。

Fermi
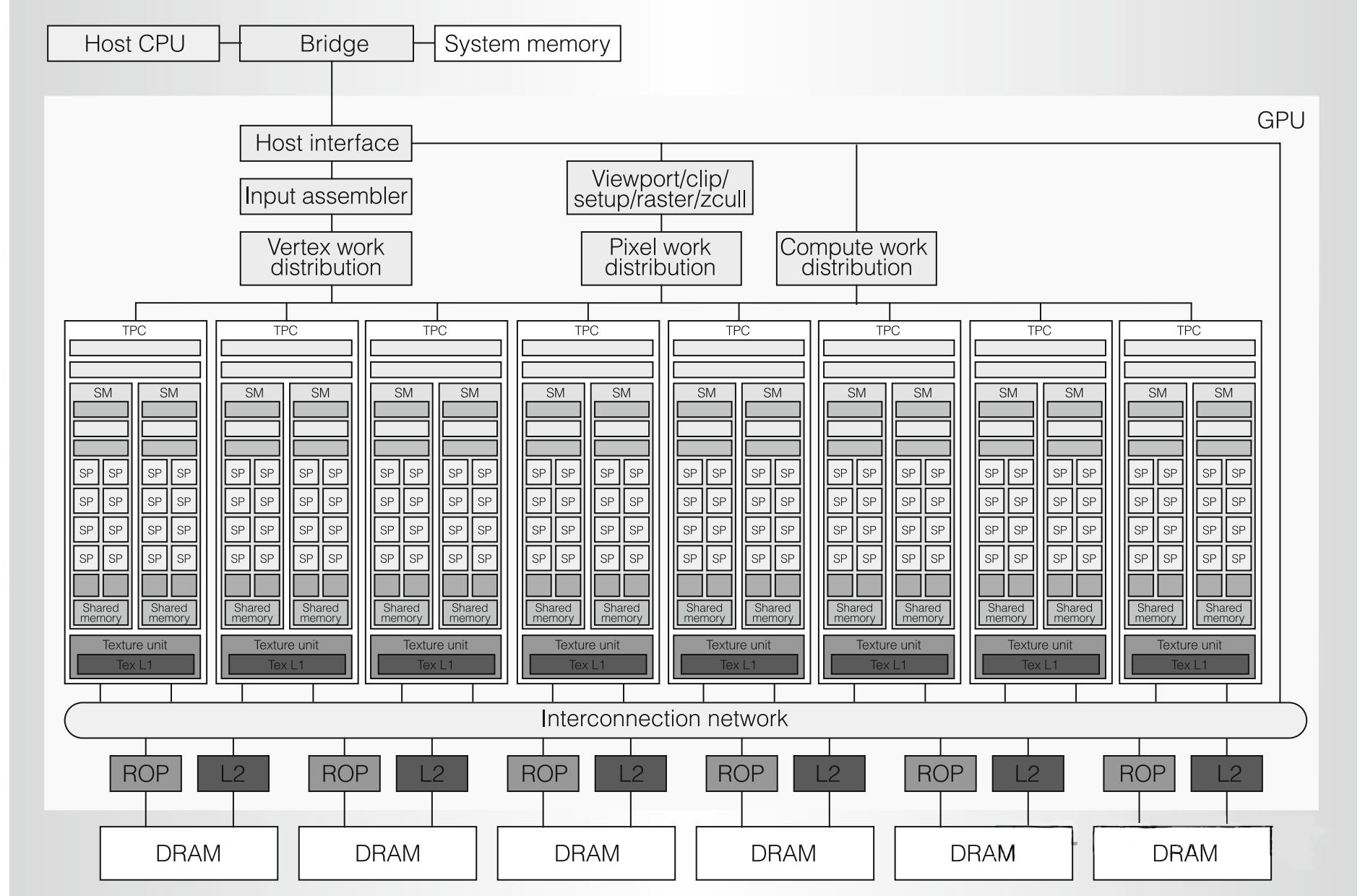
2010年推出,NVIDIA GPU是初代G80以来最重大的飞跃,是第一个完整的GPU计算架构。Fermi架构集成30亿个晶体管,台积电40nm工艺制程,512个CUDA内核,每个CUDA核心每个时钟周期可以执行一个浮点数或整数指令,采用第三代流式多处理器SM,512个CUDA核心分为16个SM,每个SM有32个CUDA内核,实现了新IEEE 754-2008浮点标准,为单精度和双精度算术提供了融合乘加(FMA)指令。
GF100,第一款基于Fermi架构的GPU,集成32亿个晶体管,专为下一代游戏与通用计算应用程序而优化的全新架构,实现了所有 DirectX 11 硬件功能,包括曲面细分和计算着色器等。每个完整的GF100包含:512个CUDA核心(SP),64个纹理单元,16个多边形引擎,1024KB L1 Cache,768KB L2 Cache,48个ROP,384Bit的GDDR5显存控制器。
框架图显示了主机接口、GigaThread引擎、4个GPC、6个内存控制器、6个ROP和一个768 KB L2 Cache,每个GPC包含4个PolyMorph引擎,ROP紧邻L2 Cache。主机接口(host interface )通过PCI-Express将GPU连接到CPU。Giga Thread全局调度器将线程块分发给SM线程调度器。

所有从Fermi架构开始的NVIDIA GPU都有GPC,GPC可以被认为是一个独立的GPU。
4个GPC,每个GPC含4个SM,共16个SM,每个SM含32个CUDA Core,共512个CUDA Core;( CUDA Core是NVIDIAGPU上的计算核心单元,用于执行通用的并行计算任务。)
第二代并行线程执行ISA:
统一地址空间,完全支持C++;针对OpenCL和DirectCompute进行了优化;完全支持IEEE 754-2008 32位和64位精度;具有64位扩展的完整32位整数路径;内存访问指令支持向64位寻址的过渡;通过预测提高性能;
改进的内存子系统:
具有可配置L1和统一L2高速缓存的NVIDIA Parallel DataCacheTM层次结构;支持ECC内存的第一款GPU;大大提高原子内存操作性能;
NVIDIA GigaThreadTM引擎:
应用程序上下文切换速度提高了10倍;并发内核执行;无序线程块执行;双向可重叠的内存传输引擎;
Kepler
2012年推出,采用台积电28nm工艺制程,整体架构与Fermi保持一致性,但思路为减少SM单元数,增加CUDA内核数,SM改名为SMX,Kepler架构中每个SM单元的CUDA内核数从Fermi架构的32个增至192个。
Kepler相较于Fermi更快!效率更高!性能更好!
Kepler架构创新功能包括:
新一代SMX,集成了几个架构创新,这不仅使其成为有史以来功能最强大的流式多处理器(SM),而且还最省电、最具编程性;
Dynamic Parallelism,这是一种能够让GPU在无需CPU介入的情况下,通过专用加速硬件路径为自己创造新的工作、对结果同步,并控制这项工作的调度的能力;
Hyper-Q允许多个CPU核同时在单一GPU 上启动工作,从而大大提高了GPU的利用率并削减了CPU空闲时间;
Grid Management Unit:使Dynamic Parallelism能够使用先进、灵活的GRID管理和调度控制系统。
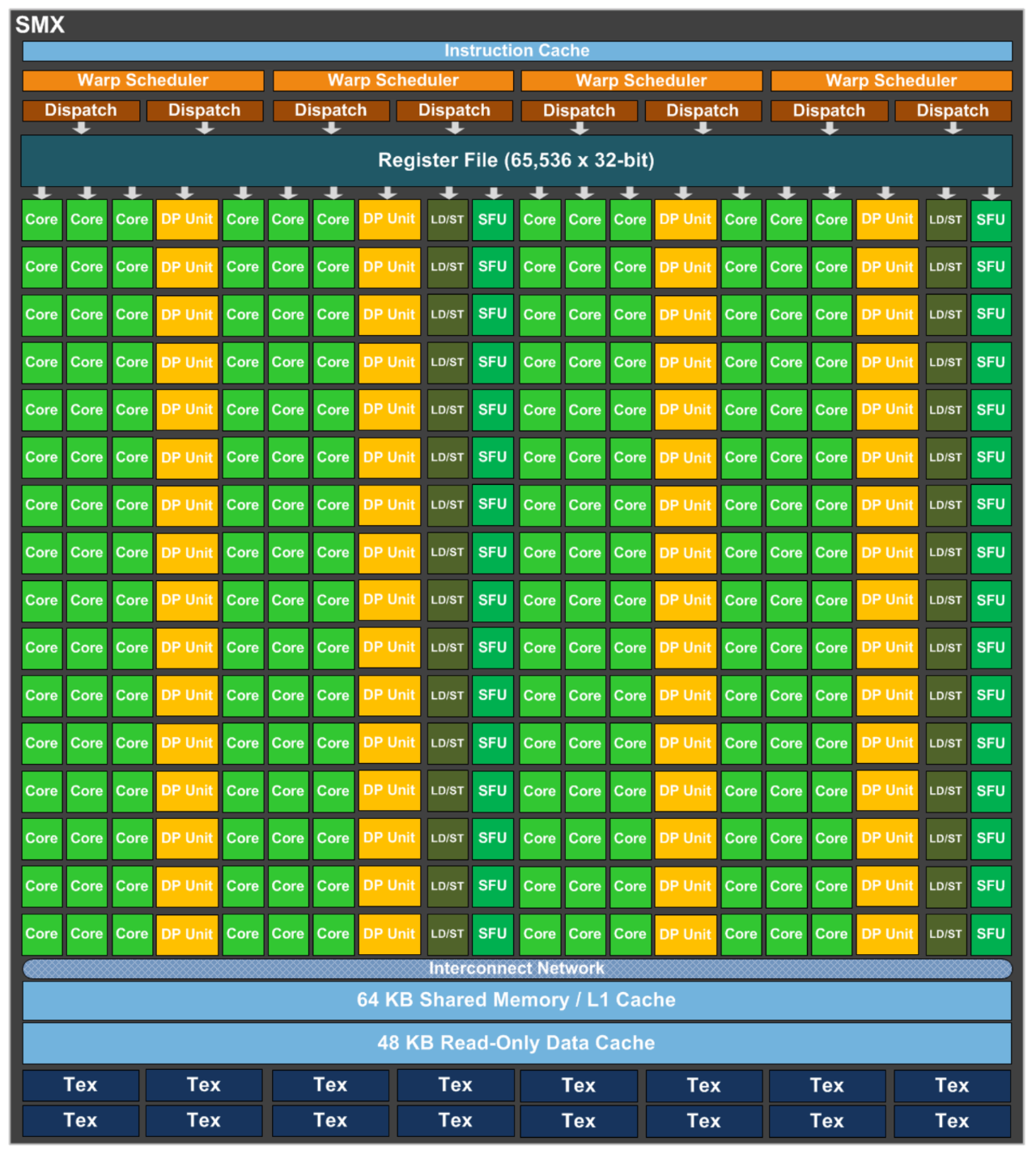
通过提供比上一代GPU更强大的处理功能以及优化和提高GPU上并行执行工作负载的新方法,Kepler GK110简化了并行程序的建设,对于高性能计算进行进一步的改革。GK110集成71亿个晶体管,192个单精度CUDA核、64个双精度单元、32个特殊功能单元(SFU)和32个加载/存储单元(LD/ST),提供超过1万亿次双精度计算浮点的吞吐量。
GK110和GK210旨在提供快速的双精度计算性能,加速专业的高性能计算工作负载,基于Kepler的GK110和GK210能够以高达高精度计算性能的1/3的速度执行双精度计算。
Maxwell
2014年推出,是先前Kepler架构的升级版,采用台积电28nm工艺制程,SM全新设计(称SMM)巧妙地模仿了4个Fermi架构SM单元2x2排列方式,每组SMM单元的CUDA核心数减少,但每个SMM单元拥有更多的逻辑控制电路,便于精确控制。
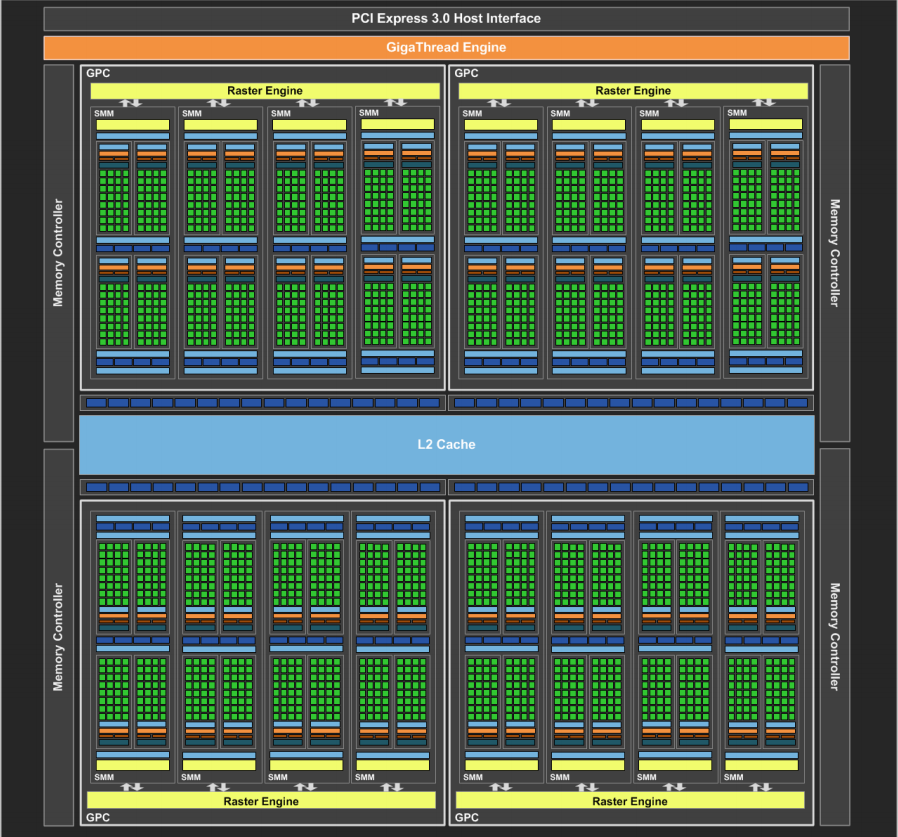
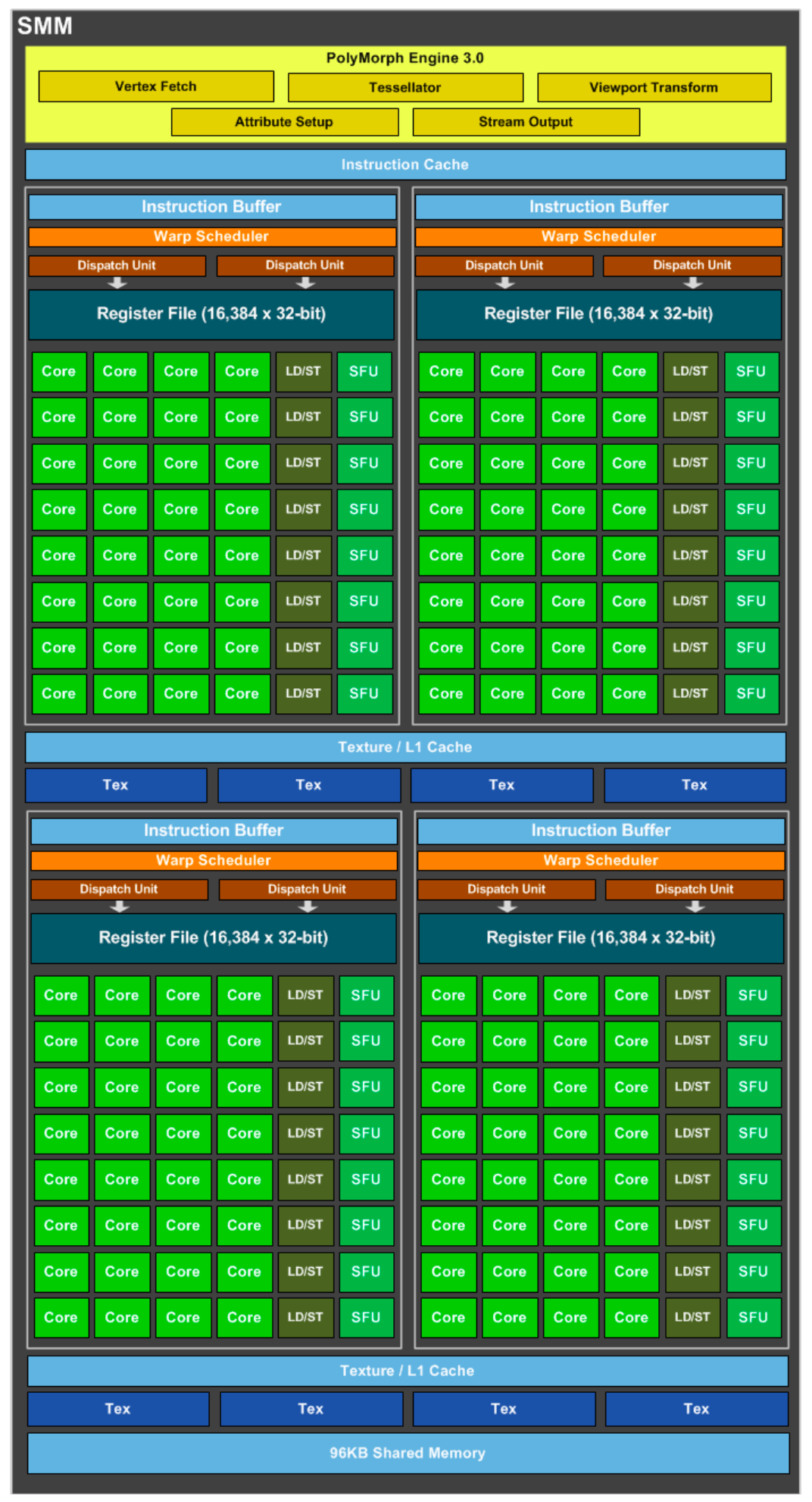
首款基于Maxwell架构的GPU为GM107,专为笔记本和小型(SFF) PC等功率受限的使用场合而设计,采用台积电28nm工艺制程,芯片尺寸148平方毫米,集成18.7亿个晶体管。针对流式多处理器采用全新设计称为SMM,GM107核心的每核心效能提升了35%,每瓦功耗比提升了一倍, 支持DirectX 12。
Pascal
2016年推出,采用台积电16nm工艺制程,集成1500亿个晶体管,首个为了深度学习而设计的GPU,支持所有主流的深度学习计算框架。关键技术包括NVIDIA® NVLink™ 高速互连技术、HBM2第二代3D堆栈式高带宽内存、依靠Async shaders从硬件层面完整实现AsyncCompute、支持DirectX 12Feature Level 12_1。
Pascal架构的GPC有6个SM,每个SM有64个CUDA Core,拥有64个FP32单元和32个FP64单元,双精度性能大幅度提升。Pascal架构核心阵容强大,包括GP100(3840个CUDA Core和60组SM单元)和GP102(3584个CUDA Core和28组SM单元)两大核心。
GP100,每个SM单元划分为2个Process Block,每个Block内藏高效处理机制,实现双重效能,包括:1个Warp Scheduler,2个Dispatch Unit;32个CUDA Core,搭载16个DP双精度运算单元,均匀分布于2条lane中,每条配备8个单元;8个LD/ST Unit;8个SFU;最亮眼之处在于引进了DP双精度运算单元,实现性能与精度的双重提升。
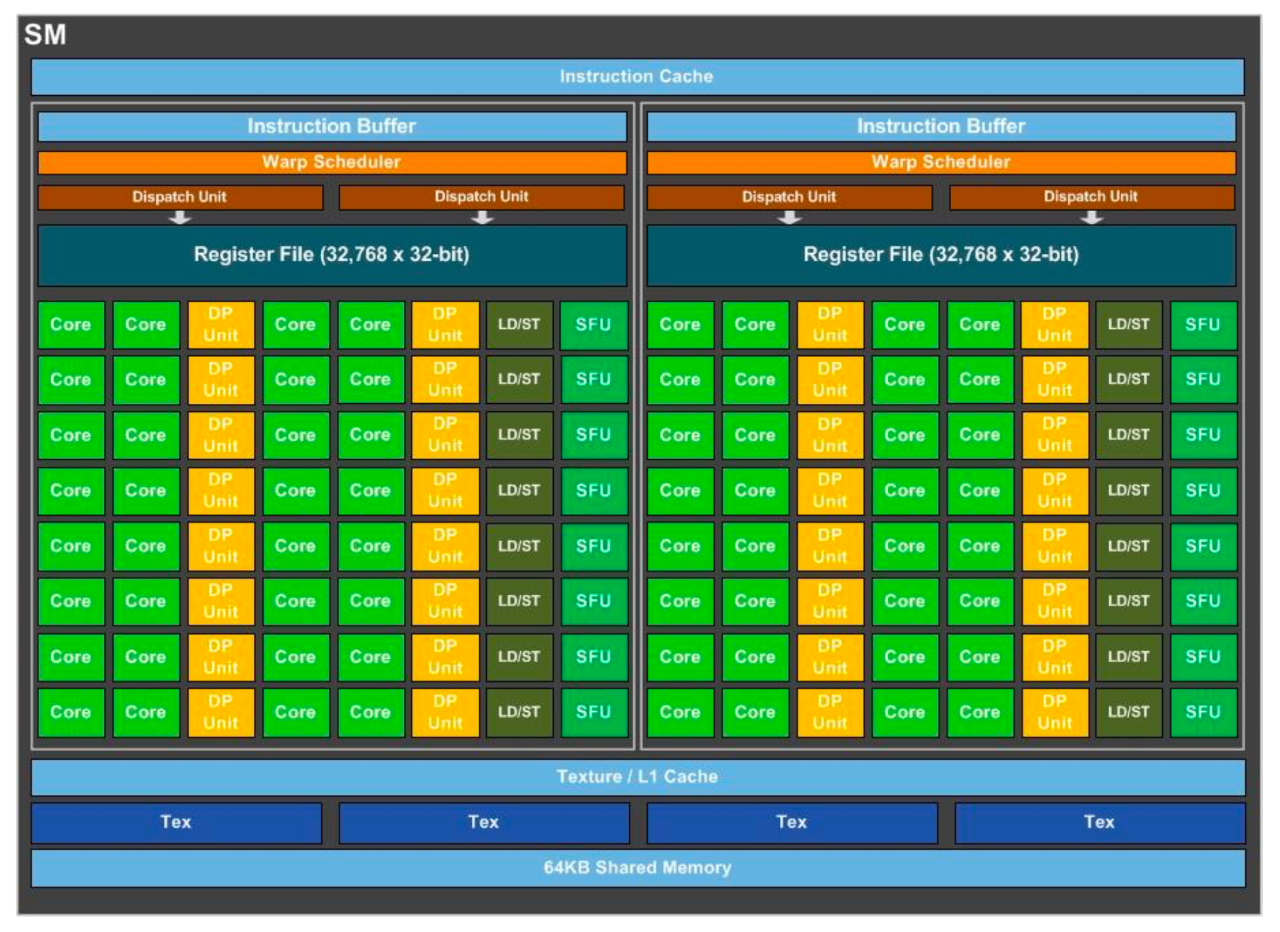
Volta
2017年推出,第一代TensorCore,采用台积电12nm工艺制程,集成210亿个晶体管,配备640个Tensor核心,每秒可提供超过一秒125teraFLOPs的深度学习效能,比上一代提速5倍以上。
在前几代架构中,一个CUDA Core在每个时钟周期里只能为一个线程执行一条浮点或整数指令,自Volta架构开始,CUDA Core被拆分为FP32与INT32两部分,每一时钟周期内,浮点和整数指令可以并行执行,显著提升计算效率。
Volta有80个SM,每个SM包括32个FP64、64个INT32、64个FP32、8个Tensor Cores。
Volta架构的GPU主要用于深度学习、科学计算与高性能计算。
GV100基于NVIDIA Volta GPU架构,采用台积电的12nm FFN工艺,晶体管数量高达221亿,封装面积高达815mm,能够提供高达每秒7.4万亿次的双精度浮点运算性能以及每秒14.8万亿次的单精度浮点运算性能和每秒118.5万亿次的深度学习浮点运算性能。GV100核心拥有6个GPC,每个GPC内部拥有7个TPC,每个TPC拥有2个SM模块,整个GV100拥有84个SM模块。进一步细分,每个SM模块中拥有64个FP32的单元、64个INT32单元、32个FP64单元以及新加入的8个张量(Tensor)单元,此外还有4个纹理单元。因此完整版本的GV100核心就拥有5376个FP32、5376个INT32、2688个FP64,672个张量单元以及336个纹理单元。内部存储模块方面,GV100设计了共享的128KB可配置L1数据缓存,L2缓存方面高达6MB。外部存储单元上,GV100设计了八个512bit的内存控制器,配合HBM2显存,组成了4096bit的规模,搭配8颗每颗2GB共16GB、1.75GHz的HBM2颗粒时,带来了约900GB/s的显存带宽。
Tesla V100集成超过210亿个晶体管,第一个在深度学习性能方面突破100TOPS的障碍的GPU,拥有43000个Tensor核心,Tensor单元性能可达120TFLOPS,L2缓存达6MB,每组SM单元的寄存文件大小总数达到20MB。第二代 NVIDIA NVLink™互连技术以超过160 GB/s 的速度连接多个V100 GPU,通过将Tensor和CUDA核心组合到统一架构中,配备Tesla V100 GPU的单个服务器可以取代数百台通用CPU服务器,可持续加速AI和HPC工作流程。

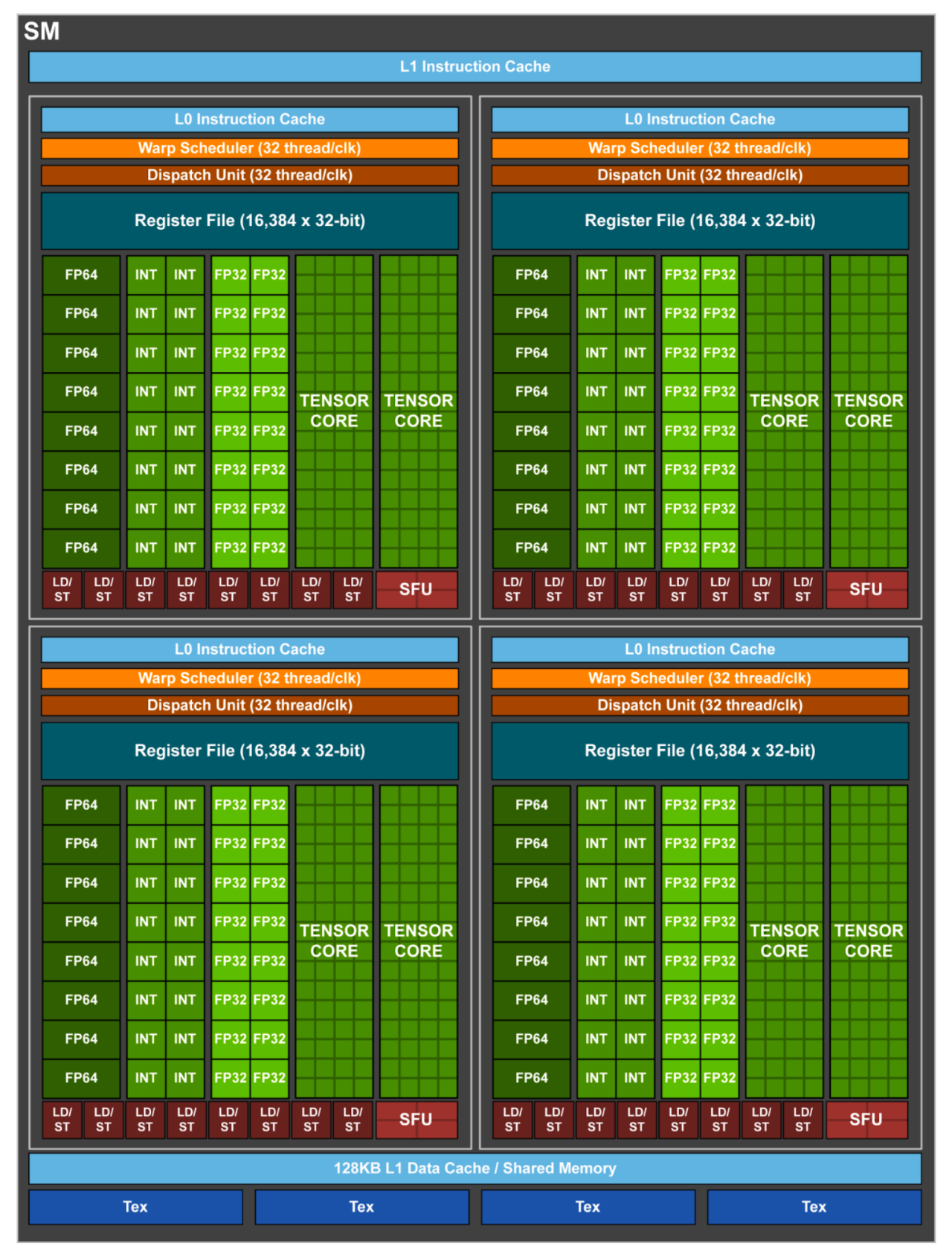
Turning
2018年推出,第二代TensorCore,采用台积电12nm工艺制程,集成186亿个晶体管,引入专门用于光线追踪的RT核心,以高达每秒10 Giga Rays的速度对光线和声音在3D环境中的传播进行加速计算,是初代G80以来最重大的飞跃。Turning配备全新的Tensor Core,每秒可提供高达500万亿次的张量运算,极大加速AI增强功能。基于Turing的GPU搭载新型流多处理器 (SM) 架构,支持高达16万亿次浮点运算,同时能够并行执行16万亿次整数运算。
TU102 GPU含6个GPC、36个TPC和72个SM,每个GPC含1个专用的光栅化引擎,2个TPC,每个TPC含2个SM,每个SM含64个CUDA Core、8个Tensor Core、1个256KB寄存器堆、4个纹理单元以及96KB的L1或共享内存,每个SM中的全新RT核心处理引擎负责执行光线追踪加速。每个显存控制器均附有8个光栅化处理单元(ROP)和512KB的L2缓存,完整的TU102 GPU由96个ROP单元和6144KB的L2缓存组成。采用第二代NVIDIA NVLink™高速互联技术,包含两个NVLink x8链路,每个链路在每个方向上均可提供高达25GB/秒的传输带宽,总计双向带宽可达100GB/秒。一块TU102 GPU共包含576个Tensor Core,每个SM中的8个Tensor核心可在每个时钟周期内总共执行512次FP16乘积累加运算,或在每个时钟周期内共计执行1024次FP运算。新添加的INT8精度模式在运作时要比该速度快一倍,即能在每个时钟周期内执行2048次整数运算。
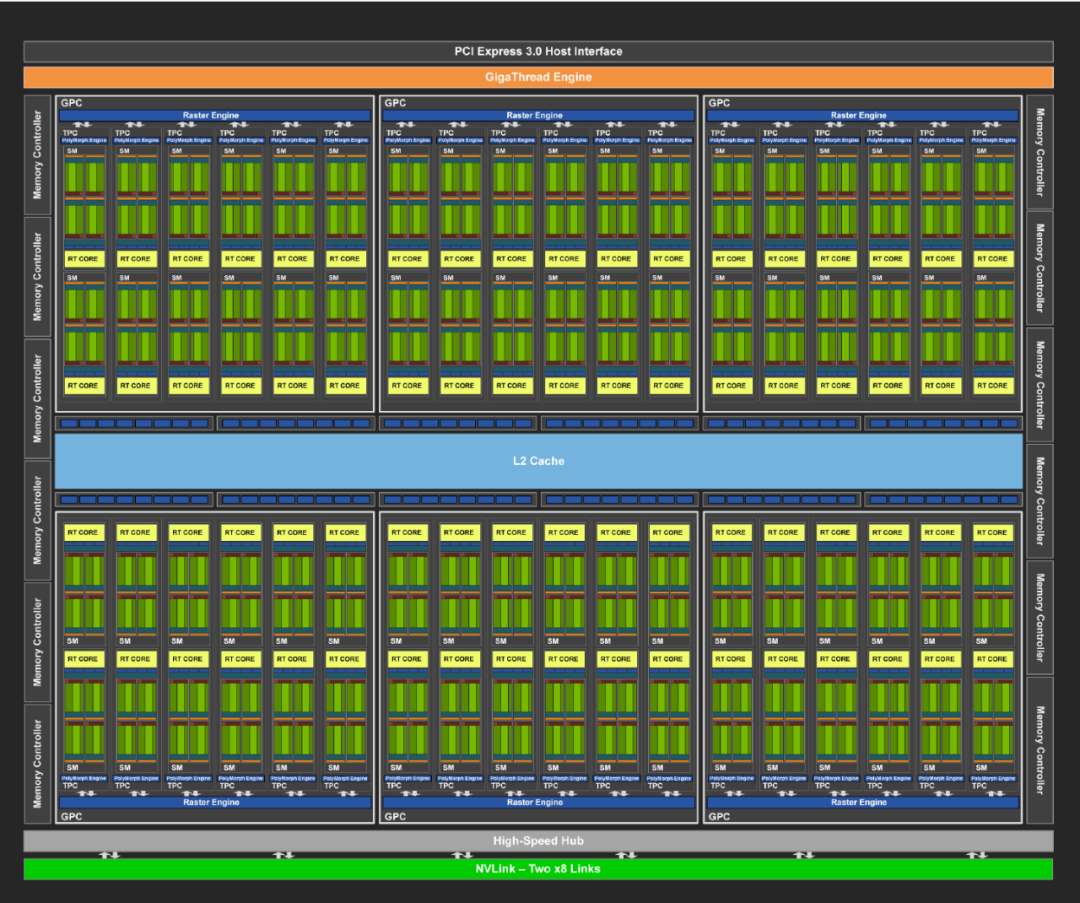
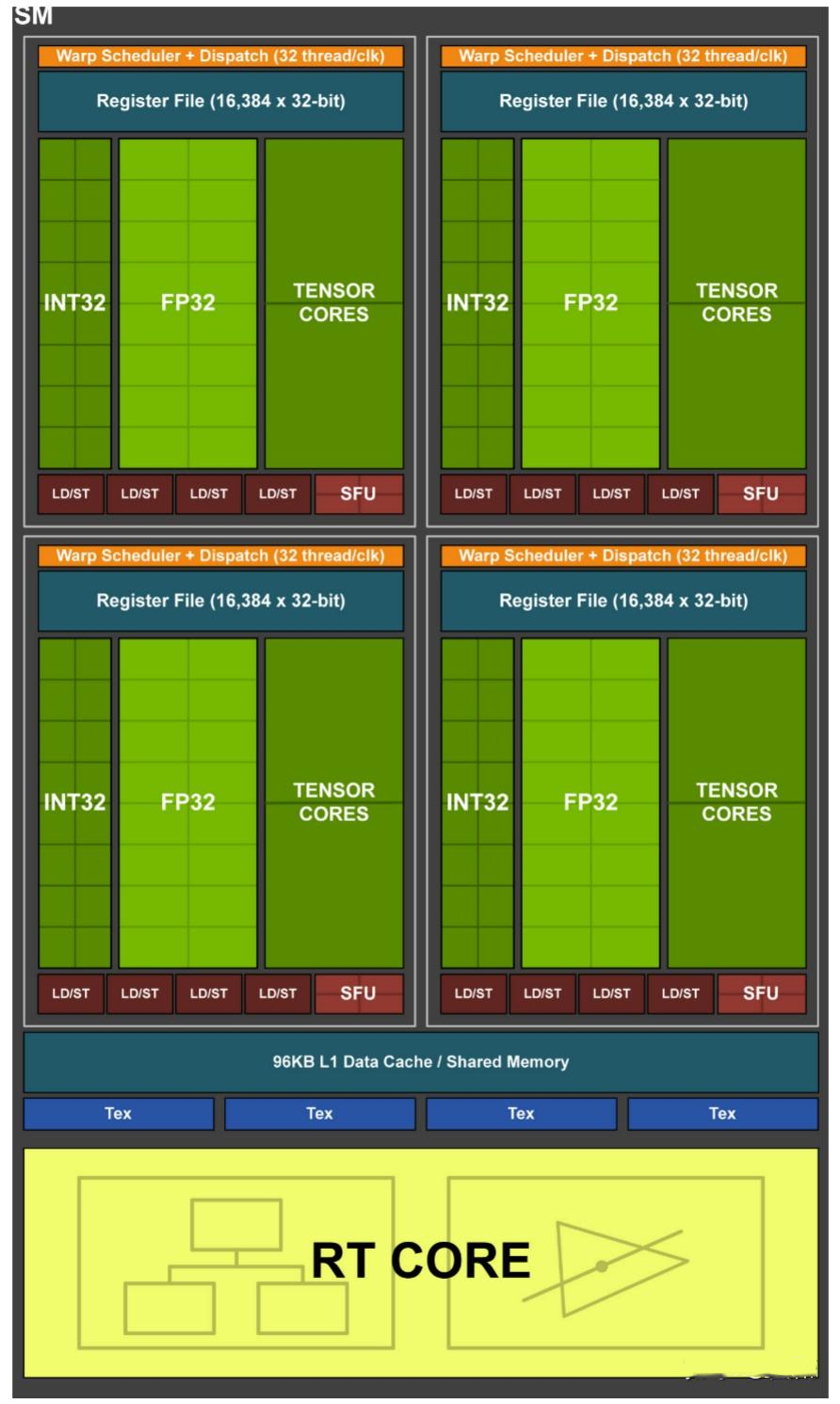
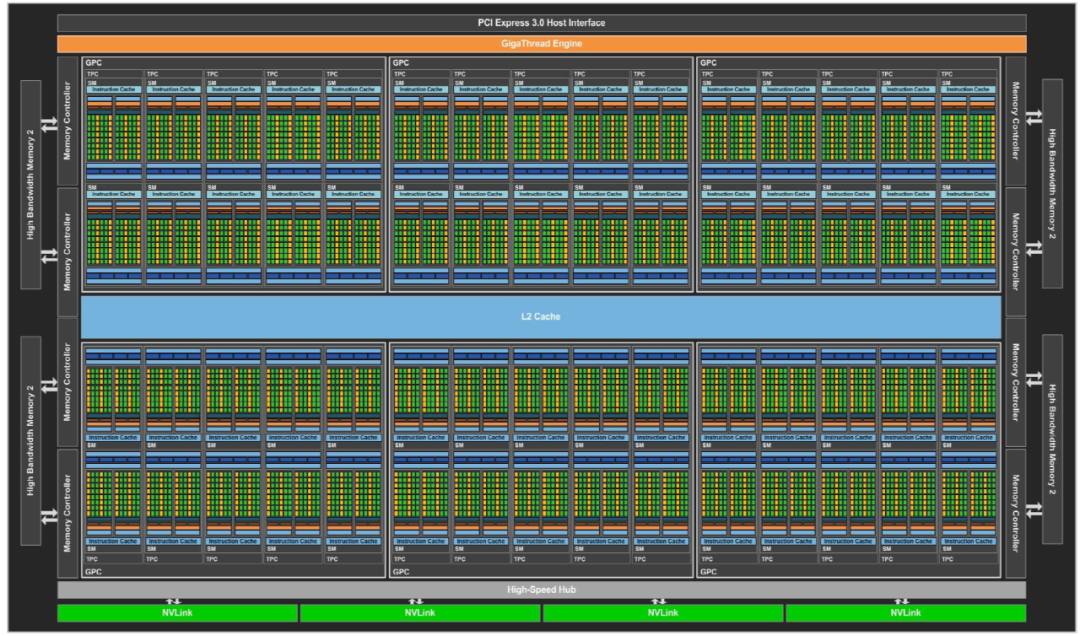
Ampere
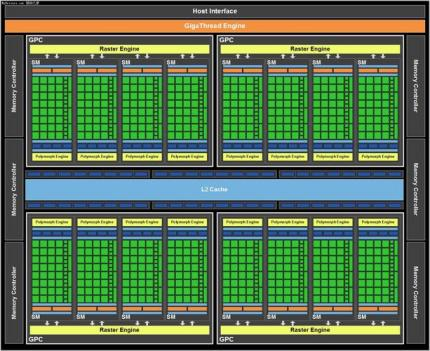
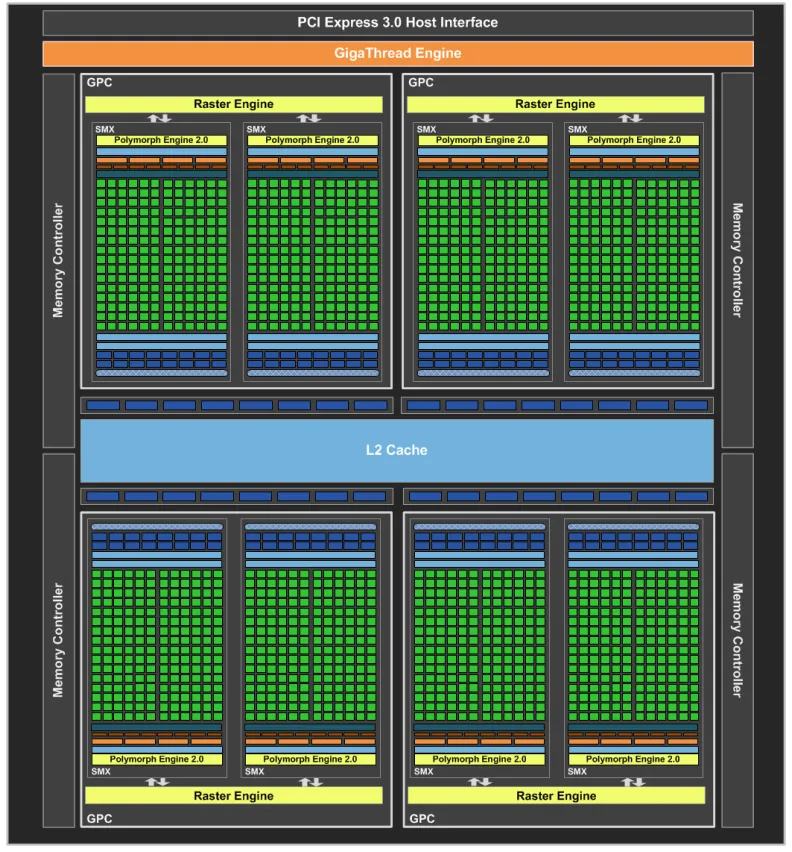
2020年推出,采用台积电7nm/三星8nm工艺制程,集成540亿个晶体管,采用六项突破性创新技术,专为弹性计算时代设计,在各种规模下能实现出色的加速,显著增加CUDA核心数量,提高每个SM的计算能力,整体性能得到大幅度提升。第三代TensorCore,采用全新精度标准Tensor Float 32 (TF32)与64位浮点(FP64),以加速并简化人工智能应用,同时将Tensor核心效能拓展至高效能运算。第二代RT核心支持光线追踪,提供更高效的光线追踪计算能力,带来更逼真的渲染效果。在A100等中引入多实例GPU(MIG)功能,将每个GPU分割成多个GPU实例,各自在硬件中独立且受保护,可以运行不同任务。Ampere GPU支持PCI Express 4.0标准,提供比前一代GPU更高的数据传输速度。
A100采用全新的Ampere架构,7nm工艺制程,集成540亿个晶体管,拥有高达6912个CUDA Core,共108个SM,每个SM含64个FP32、64个INT32、32个FP64、4个Tensor Core,提供40GB和80GB显存两种版本,80GB的版本将GPU显存增加一倍,提供超快速的显存宽带秒超过2 万亿TB/s,可实现高达19.5 TFLOPS的FP32浮点性能和156TFLOPS的深度学习性能,最大功耗达到400W。A100采用双精度 Tensor Core,结合80GB的超快GPU显存,研究人员可以在A100上将10小时双精度仿真缩短到4小时以内。A100结合 MIG 技术更大限度地提高GPU加速的基础设施的利用率,推理吞吐量可提升高达7倍。
GA100 GPU的完整实现包括以下单元:
· 每个完整GPU 含8个GPC,8个TPC/GPC,2个SM/TPC,16个SM/GPC,128个SM
· 每个完整GPU含 64个FP32 CUDA内核/ SM,8192个FP32 CUDA内核
· 每个完整GPU 含4个第三代Tensor核心/SM,512个第三代Tensor核心
· 6个HBM2堆栈,12个512位内存控制器
GA100 GPU的A100 Tensor Core GPU实现包括以下单元:
· 7个GPC,7个或8个TPC/GPC,2个SM/TPC,最多16个SM/GPC,108个SM
· 每个GPU含64个FP32 CUDA内核/SM,6912个FP32 CUDA内核
· 每个GPU含4个第三代Tensor内核/SM,432个第三代Tensor核心
· 5个HBM2堆栈,10个512位内存控制器
下图显示具有128个SM的完整GA100 GPU,A100基于GA100,具有108个SM。

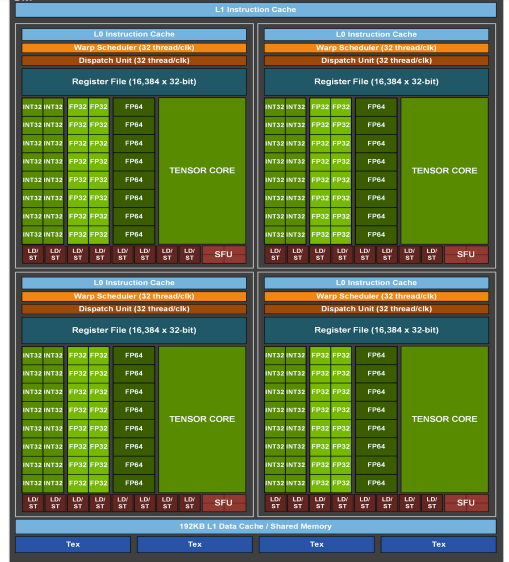
Hopper
2022年推出,采用台积电4nm工艺制程,集成800亿个晶体管,采用五项突破性创新技术为 H100 Tensor Core GPU 提供动力支持,通过Transformer引擎推进TensorCore技术的发展,旨在加速AI模型训练,Hopper Tensor Core应用混合的FP8和FP16精度,大幅加速Transformer模型的AI计算,并与Transformer引擎和第四代NVIDIA® NVLink® 相结合,可使HPC和AI工作负载的加速实现数量级提升。第二代MIG功能,MIG 技术支持将单个GPU分为七个更小且完全独立的实例,进一步支持各种工作负荷。
H100采用台积电4nm工艺制程,CoWoS 2.5D晶圆级封装,集成800亿个晶体管,是首款支持PCIe 5.0的GPU,也是首款采用HBM3的GPU,可实现3TB/s的显存带宽,拥有132组SM计算单元,总计高达16896个CUDA Core、528个Tensor Core、50MB二级缓存。
完整版的GH100核心内建有8个GPC、72个TPC、144个SM,每个SM有128个FP32 CUDA Core,总计18432个,核心内置576个第四代Tensor Core张量核心,匹配60MB二级缓存。显存方面,采用5颗HBM3显存,带来5120-bit位宽和80GB容量,总带宽高达3TB/s,应用第四代NVLink和PCIe第5代。
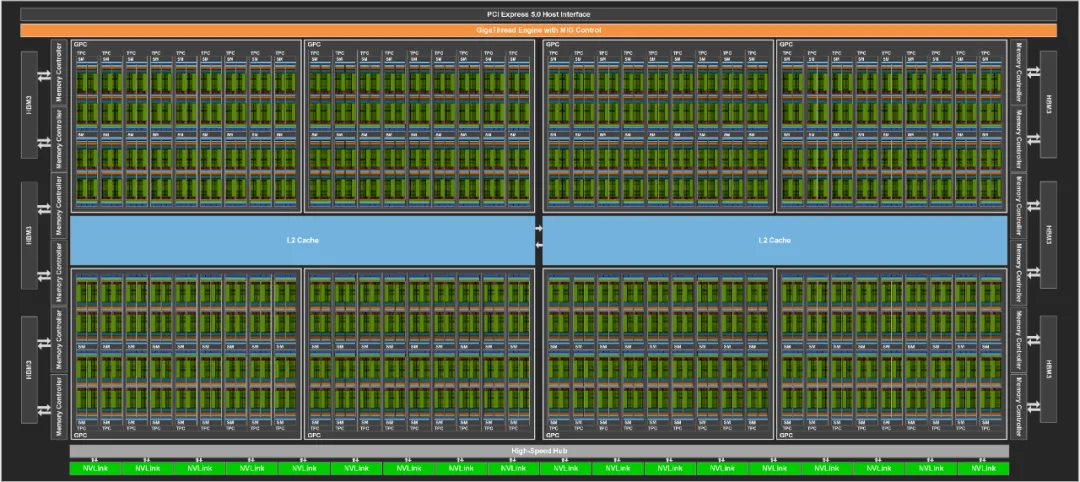

Ada Lovelace
2022年推出,第三代RT核心与第四代TensorCore,采用TSMC 4N定制工艺技术,实现了高达2倍的性能功耗比飞跃,拥有超过760亿个晶体管和18000个CUDA Core,设计重点在于提升光线追踪效率、加速AI计算能力、大幅提高图形处理性能,旨在为游戏、创作、AI和高性能计算提供革命性的性能提升,使用该架构的GPU有RTX 5000、RTX4500、RTX4000桌面GPU,皆采用台积电4nm工艺制程,具有以下特点:
NVIDIA CUDA内核:单精度浮点吞吐量是上一代的2倍;
第三代RT核心:光线追踪吞吐量较上一代提高了2倍,并且可以同时进行光线追踪、着色或降噪;
第四代TenosrCore:AI训练性能较上一代提高了2倍,并且支持FP8数据格式;
DLSS3:借助AI的力量,为实时图形带来更高的真实感与交互性;
更大的显存容量:RTX5000提供32GB GDDR6显存,RTX4500提供24GB GDDR6显存,RTX4000提供20GB GDDR6显存,这些显存支持纠错码技术,可以保证处理大型3D模型、渲染图像、仿真和AI数据集时不出错;
扩展现实能力:支持高分辨率的增强现实与虚拟现实设备,为创造AR、VR和混合现实内容提供高性能图形。
AV1编码器:新架构的GPU配备了支持AV1编码的第八代NVIDIA编码器。
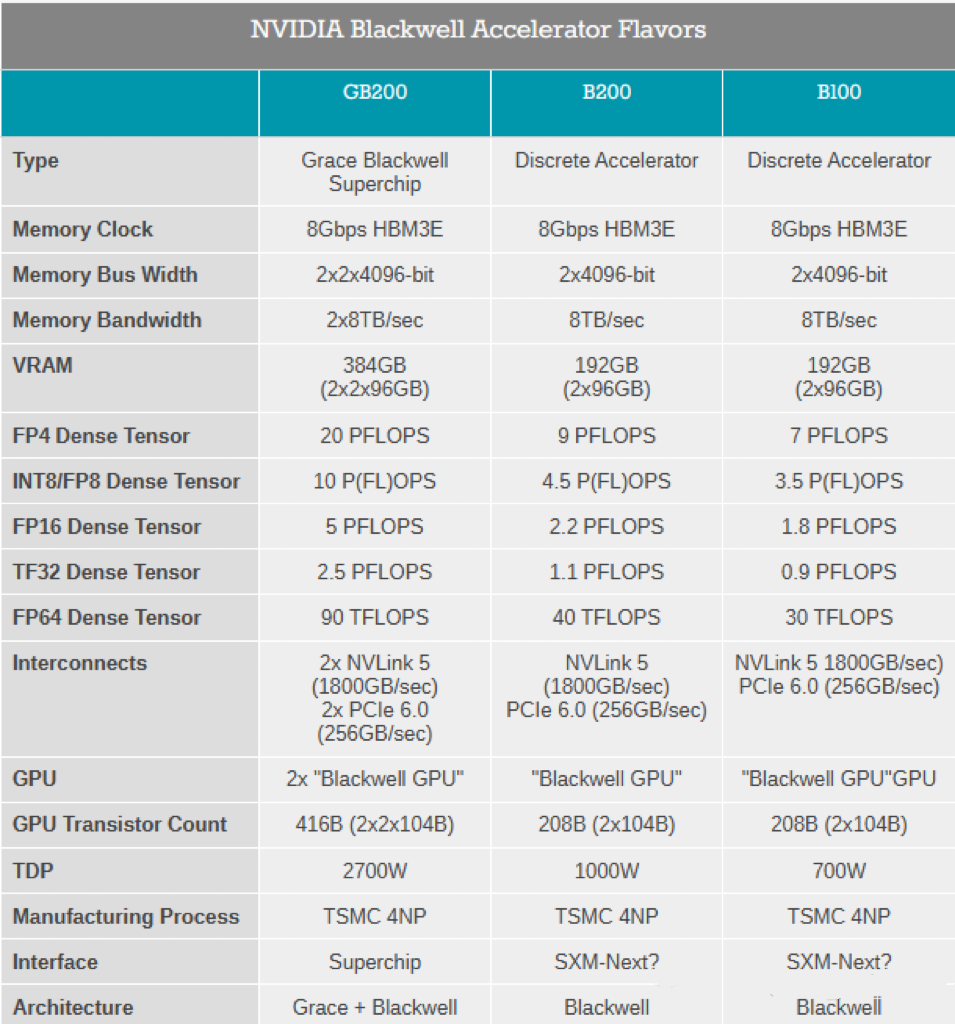
Blackwell
2024年推出,Blackwell架构的GPU集成2080亿个晶体管,采用台积电4NP工艺,NVIDIA称其可实现在十万亿级参数模型上的AI训练和实时LLM(大语言模型)推理。
六大核心技术:
全球最强大芯片:采用统一内存架构+双芯配置,通过10 TB/s的片间互联,将GPU裸片连接成一块统一的GPU;
第二代Transformer引擎:将新的微张量缩放支持和先进的动态范围管理算法与TensorRT-LLM和NeMo Megatron框架结合,使Blackwell具备在FP4精度的AI推理能力,可支持2倍的计算和模型规模,能在将性能和效率翻倍的同时保持混合专家模型的高精度。
第五代NVLink:为每个GPU提供1.8TB/s双向宽带,支持多达576个GPU间的无缝高速通信,适用于复杂大语言模型。
RAS引擎:确保可靠性、可用性、可维护性的专用引擎,增加芯片级功能,利用基于AI的预防性维护来进行诊断和预测可靠性问题。最大程度延长系统正常运行时间,提高大规模AI部署弹性,同时降低运营成本。
安全AI:机密计算功能保护AI模型和客户数据。
解压缩引擎:支持最新格式,加速数据库查询,提供数据分析和数据科学的最高性能。
B200:首款Blackwell架构芯片,集成2080亿个晶体管,192GB高速HBM3e显存,AI性能每秒20千万亿次浮点计算。
GB200:由两个B200 GPU和Grace GPU相连,可为LLM推理工作负载提供30倍的性能。与H100相比,GB200的性能是它的7倍且成本和能耗更低。
NVIDIA,引领图形处理器技术革新的科技巨头,其GPU架构的演进历程堪称一部波澜壮阔的史诗。在NVIDIA的GPU架构演进史中,每一个里程碑都代表着一次技术的飞跃,从最初的GeForce系列到如今的Blackwell架构,NVIDIA不断刷新着我们对高性能计算的认知。
近年来,NVIDIA的GPU架构创新步伐更是愈发加快,而在近期,NVIDIA已经透露了下一代数据中心GPU架构“Rubin”的相关信息。这款全新的GPU架构将采用全新的HBM4技术,为数据中心带来前所未有的性能提升。可以预见,随着“Rubin”等新一代GPU架构的推出,NVIDIA将在未来继续引领GPU技术的发展潮流。让我们拭目以待,期待NVIDIA在未来的GPU架构演进史中书写更加辉煌的篇章!
下期预告:AMD GPU架构演进!
参考资料:
[1]https://cloud.tencent.com/developer/article/2295025
[2]https://zhuanlan.zhihu.com/p/640324969
[3]https://www.nvidia.cn/design-visualization/technologies/turing-architecture/
[4]https://baijiahao.baidu.com/s?id=1746292653855705036
[5]https://blog.csdn.net/NUCEMLS/article/details/136309677
[6]https://mp.weixin.qq.com/s/Eb_30Qk1xHauhhyDD1tTFA
[7]https://www.bilibili.com/read/cv25720826/
[8]https://www.163.com/dy/article/ITL4TJ4K0511CUMI.html
[9]https://blogs.nvidia.cn/blog/nvidia-blackwell-dgx-generative-ai-supercomputing/